
Recueil de questions posées à :
L’oral de l’examen de vérification d’aptitudes aux fonctions de programmeur de système d’exploitation (MAJ selon Programme de l’épreuve oral - arrêté du 11 décembre 2006)
L’épreuve commune de l’écrit de l’examen de vérification d’aptitudes aux fonctions de programmeur de système d’exploitation
l’épreuve de spécialité du concours IEF Informatique
SOMMAIRE
la représentation de l’information
1 Les fonctions arithmétiques ?
2 Qu’est-ce que Big Indian et Little Endian ?
3 Comment se présente un nombre en virgule flottante et en virgule fixe?
4 Qu’est-ce qu’une instruction ?
5 Qu’est qu’un code détecteur d’erreur, un code correcteur d’erreur ?
6 Qu’est qu’un contrôle de parité, de double parité ?
7 Qu’est ce qu’un code de Hamming ?
9 Composants d'une carte mère et leurs fonctions ?
10 Archi RISC par rapport à CISC ?
11 Quels sont les différents modes d’adressage de la mémoire pour un processeur ?
12 Les types de mémoires (temps d'accès, capacité, coût) ?
13 Qu'est-ce qu'une mémoire associative ? Avantages ?
14 Avantages, inconvénients de la technologie RAID ?
15 Différence entre RAID 0 et Raid 1 ? Description du Raid 5 ?
16 Comment se caractérise la transmission de l’information ?
17 Qu’est-ce que la « gigue » ? Quelles sont les solutions pour palier à la gigue ?
19 Différences entre Half et Full duplex ?
20 Différences entre interruption, exception et déroutement ?
21 Qu’est-ce que la multiprogrammation ?
22 Qu’exprime le taux de multiprogrammation ?
23 Comment est segmentée la mémoire centrale d’un ordinateur ?
24 Qu’est ce que la mémoire virtuelle ?
26 Quelles sont les différentes stratégies d’allocation de la mémoire ?
27 Qu’est-ce qu’un progiciel ?
28 Définition d'un processus ? Etat, Ordonnancement ?
29 Définition d’un processus UNIX ?
31 Qu’est–ce qu’une exécution en mode noyau ou utilisateur ?
32 Qu’est-ce que la commutation de contexte ?
33 Comment se décompose la segmentation de la mémoire pour un processus ?
Communication inter ou intra processus
35 Quels sont les différents moyens de communication inter processus ?
36 Quels sont les différents moyens de synchronisation entre les processus ?
38 Qu’est-ce qu’un interblocage ?
39 Quelles sont les solutions pour éviter les interblocages ?
40 Qu’est-ce qu’un sémaphore ?
41 Citer des problèmes récurrents auxquelles répond l’utilisation des sémaphores ?
42 Qu’est-ce qu’un Mutex (exclusion mutuelle) ?
43 Qu’est-ce que l’inversion de priorité ?
44 Qu’est-ce qu’un signal (UNIX)?
45 Qu’est qu’un système d’exploitation ?
46 Qu’elles sont les fonctions d’un système d’exploitation ?
47 Citez des exemples de système d’exploitation ?
48 Les systèmes d'exploitation réseau ?
Architectures de systèmes ou de processus
49 Quels sont les avantages et les inconvénients d’un système centralisé ?
50 Quels sont les avantages et les inconvénients d’un système distribué ?
51 Qu’est qu’une architecture Client/Serveur?
52 Architectures 3 tiers ? N tiers ?
53 Qu’est-ce qu’un machine virtuelle ? Différence avec runtime ?
54 Garbage collector ? Les algorithmes ?
55 A quoi sert un masque de réseau ?
56 Qu’est-ce qui différencie une adresse de classe A, B et C ?
57 Qu’est-ce qu’une adresse Ethernet ?
58 Qu’est-ce qu’un adresse de diffusion ?
59 Différentes topologies réseaux logiques ?
61 Quelles sont les différences entre IPV4 et IPV6 ?
63 Les types de réseau en ordre croissant ?
64 Définition Internet, Intranet, Extranet ?
67 A quoi sert la qualité de service sur un réseau IP ?
68 Quels sont les critères de la qualité de service ?
69 Qu’est-ce que le routage ? Citez et expliquez les différents algorithmes existants ?
71 Quels sont les risques en sécurité pour un réseau WIFI ?
72 Quelles sont les techniques pour sécuriser les réseaux sans fils WIFI ?
74 Quelles sont les différentes architectures du WPA ?
77 Qu'est-ce q'un VLAN ? Quels sont ses avantages ?
79 Quelles sont les normes qui définissent les VLAN ?
80 Quels sont les types d’équipement qui gère les VLAN ?
81 Qu'est-ce que RPV ? Correspondance de ses protocoles selon le modèle OSI ?
84 Qu’est-ce que l’UDP ? Qu’est-ce qui le caractérise ?
85 Qu’est-ce que le Diffserve ?
86 Qu’est-ce que le Intserve ?
87 Qu’est-ce qu’un web service ?
88 Qu'est-ce qu'un méta annuaire ?
90 Quelles sont les fonctions du protocole LDAP ? Que permet-il ?
91 Quelles sont les différences entre un annuaire et une base de donnée ?
92 Serveur de temps ? Architecture pour en gérer plusieurs ?
93 Mécanisme de SSO (Single Sign On)? Architectures ?
95 Qu’est-ce que la MIB ? Usage et rôle ?
96 Quelles sont les contraintes du temps réel sur IP ?
97 La téléphonie sur Internet ?
98 Qu’est-ce que le protocole SIP ?
99 Quelles sont les contraintes spécifiques à la vidéo conférence sur IP ?
100 Différences entre un Switch et un Hub. Que permet de plus le Switch ?
101 Qu’est ce qu’un Répéteur ?
105 Qu’est-ce qu’un passerelle ?
106 Les différentes normes de câblages Ethernet ? Débits et portées ?
107 Qu’est-ce que Manchester Bi-Phasé ?
108 Les différents types d’attaques par réseau?
110 Quel résultat du scan de la pile TCP/IP d'un serveur ?
111 Comment protéger un serveur des tentatives de scan de la pile TCP/IP ?
112 Objectifs d'un scan ? Comment masquer une intrusion sur un serveur ?
114 Qu’est-ce qu’un IDS (détecteur d'intrusion) ?
115 Quelles sont les différentes techniques de détections d’un IDS ?
116 Quelles sont les différentes actions d’un IDS ?
119 Entrepôt de données (data warehouse) ?
120 Quelles sont les différences entre un entrepôt de données et une base de données ?
121 Qu’est-ce qu’un Datamart ?
123 DAS, NAS et SAN ? Mode d'accès aux données ?
124 Qu'est-ce que la virtualisation du stockage de donnée ?
126 Quels sont les objectifs (les 4 principes) de la sécurité informatique ?
127 Quelles sont les moyens mis en ouvre pour s’assurer de la sécurité d’un système informatique ?
128 Décrivez de manière détaillée la sécurité d’un centre informatique ?
130 Quelles sont les différentes techniques de recherche de virus par un antivirus?
131 Qu’est-ce que le Buffer Overflow?
132 Quels sont les objectifs de la cryptographie ?
133 Quelles sont les différences entre un chiffrement asymétrique et un chiffrement symétrique ?
134 A quoi sert un certificat ?
136 Les familles d'algorithme de chiffrement (nom, mode de fonctionnement, exemple) ?
137 A quoi sert une fonction de hachage ?
138 Citez des exemples d’algorithme de chiffrement symétrique et expliquez leur fonctionnement ?
139 Citez des exemples d’algorithme de chiffrement asymétrique et expliquez leur fonctionnement ?
140 Citez des exemples de fonctions de hachage et expliquez leur fonctionnement ?
141 Les fonctions d'un CTI ? Citez différentes architectures ?
143 Qu’est-ce que du pseudo-code (ou langage intermédiaire) ?
144 Qu’est-ce qu’un langage impératif ?
145 Qu’est-ce qu’un langage procédurale (ou fonctionnel) ?
146 Les différences entre langage procédurale (ou navigationnel) et assertionnel ?
147 Les différences entre un compilateur et un interpréteur ?
148 Programmation événementielle ?
149 Les catégories de langages ?
150 Qu’est-ce qu’un Framework ?
152 Quelles différences entre exécutable compilé en statique et en dynamique ?
153 Quelles sont les informations rajoutées à un programme compilé en mode « Debug » ?
154 Avec quoi peut travailler une équipe de programmeur ?
155 Qu’est-ce qu’un sous-programme réentrant ?
159 La surcharge de classe, de fonction ?
160 Différence entre héritage statique et dynamique ?
161 Qu’est-ce qu’un algorithme ? Caractéristiques ?
162 Récursivité ? Structures adaptées pour ça ?
163 Quelles sont les différentes techniques de parcours d’arbres ?
165 Les algorithmes de tri ? Ordre de rapidité ?
166 Cycle de vie du logiciel ?
168 Citez et expliquez des méthodes d’analyse ?
169 Qu’est-ce qu’un Design Pattern ?
172 Quels sont les différents modèles logiques d’une BD ?
174 Différences entre un SGBD et la gestion de fichiers ?
175 Citez des SGBD OpenSources ?
176 Qu’est-ce qu’un jointure ?
177 Quelles sont les 4 propriétés essentielles d'un sous système de traitement de transactions ?
181 Quels sont les objectifs de la licence GNU GPL ?
184 Single Unix Specification ?
185 CNIL ? Rôle, quand rentrer en contact avec elle ?
186 Définition de la qualité au sens ISO ? Qualité interne et externe ?
190 Qu'est-ce qu'XML (parser + DTD) et ces fonctionnalités. différence par rapport à SGML ?
191 Quel est le rôle d’une DTD ? Qu’est-ce qu’un document bien formé ou valide ?
193 Qu’est-ce qu’un Workflow ?
194 Quelles sont les différentes typologies de workflow ?
195 Qu’est-ce qu’un moteur de workflow ?
196 EAI (Enterprise Application Integration) ?
197 Qu’est ce que l’informatique décisionnelle ?
201 Qu’est-ce qu’un service dans une architecture SOA ?
202 Qu’est-ce que l’urbanisation?
Ce sont des principes d’organisation des octets en mémoire. Ils définissent la position des octets d’un entier.
Soit A un entier codés sur 64 bits, Ax avec l’octet d’indice x de A
Little Indian : famille de processeur x86, Vax
Adresse 0 :
|
A3 |
A2 |
A1 |
A0 |
Adresse 4 :
|
A7 |
A6 |
A5 |
A4 |
Big Endian : famille de processeur IBM 360/367, 68x00 Motorolla, PowerPC
Adresse 0 :
|
A0 |
A1 |
A2 |
A3 |
Adresse 4 :
|
A4 |
B5 |
B6 |
A7 |
Virgule fixe :
|
K partie entière |
K décimale |
K nombre de bit
Le K de gauche représente la partie entière du nombre
Le K de droite la partie décimale
Virgule flottante :
N = M x BE N : Nombre M : Mantisse E : Exposant B : Base
La mantise donne une précision finie. Si la taille de la mantise augmente alors la précision augmente aussi.
Stockage en mémoire IEEE 754 (32 bits et 64 bits) :
|
SM Signe de la Mantise 1 bit 1 bit |
E Exposant 8 bits 11 bits |
M Mantise 23 bits 52 bits |
Une instruction est une opération exécutable par un processeur sur des données. Elle se compose d’un code opératoire et d’opérandes
Code détecteur d’erreur :
C’est une information (1 ou plusieurs bits) rajouter à un groupe de bit permettant de vérifier si une erreur existe.
Exemples : contrôle de parité ; contrôle de double parité
Code correcteur d’erreur :
C’est une information (1 ou plusieurs bits) rajouter à un groupe de bit permettant de reconstituée l’information initialise si une erreur s’est introduite.
Exemple : code de Hamming, CRC.
Contrôle de parité :
Le control de parité est une méthode pour détecter des erreurs dans des données (ensemble de bits). Le principe consiste à rajouter 1 bit qui indique sur un nombre de bits surveillés, si le nombre de bit à 1 est pair ou impair.
Contrôle de double parité :
C’est un contrôle de parité en ligne et en colonne sur un groupe de bits rangés en tableau à 2 dimensions.
C’est un code correcteur de d’erreur.
M + k = n bits avec K bits de parité
Cyclic Redondant Coding est un code correcteur d’erreur.
Ses bits de contrôle sont générés à partir d’un polynôme appliqué sur les données à surveiller.
RISC : Reduced Intruction Set Computer
CISC : Complex Instrucion Set Computer
|
Registre |
Add R4, R3 |
R4 <= R4 + R3 |
La valeur est dans un registre |
|
Immédiat ou littéral
|
Add R4, #3 |
R4 <= R4 + 3 |
Pour les constantes |
|
Déplacement ou basé |
Add R4, 100(R1) |
R4 <= R4 + M [100 + R1 |
Accès aux variables locales |
|
Indirect par registre |
Add R4, (R1) |
R4 <= R4 + M [R1] |
Accès en utilisant un pointeur ou une adresse calculée |
|
Direct ou absolue |
Add R4, (1001) |
R4 <= R4 + M [1001] |
Accès aux variables statiques |
|
Indirect par mémoire |
Add R4, @(R1) |
R4 <= R4 + M [M [R1] ] |
Si R1 est l’adresse d’un pointeur p alors ce mode donne *p |
|
Indexé étendu |
Add R4, 100(R1)[R3] |
R4 <= R4 + M [ 100 + R1 + R3*d ] |
|
|
Auto incrément |
Add R1, (R2) + |
R4 <= R4 + R3 |
|
|
Auto décrément |
Add R4, - (R2) |
R4 <= R4 + R3 |
|
Dans l’ordre croissant du temps d’accès et des capacités :
registre du CPU,
mémoire cache,
mémoire centrale ou mémoire vive (RAM),
mémoire d’appuis (Swap),
mémoire de masse.
Caractéristiques techniques :
La capacité, représentant le volume global d'informations (en bits) que la mémoire peut stocker ;
Le temps d'accès, correspondant à l'intervalle de temps entre la demande de lecture/écriture et la disponibilité de la donnée ;
Le temps de cycle, représentant l'intervalle de temps minimum entre deux accès successifs ;
Le débit, définissant le volume d'information échangé par unité de temps, exprimé en bits par seconde ;
La non volatilité caractérisant l'aptitude d'une mémoire à conserver les données lorsqu'elle n'est plus alimentée électriquement.
Ainsi, la mémoire idéale possède une grande capacité avec des temps d'accès et temps de cycle très restreints, un débit élevé et est non volatile.
Néanmoins les mémoires rapides sont également les plus onéreuses. C'est la raison pour laquelle des mémoires utilisant différentes technologiques sont utilisées dans un ordinateur, interfacées les unes avec les autres et organisées de façon hiérarchique.
Figure 22 : Hiérarchie mémoire en fonctions du temps d'accès et de la capacité
Mémoire cache : centaines de Ko à 4 Mo, mémoire très rapide ; entre CPU et la RAM ; stocke instruction et données ; mémoire associative
Mémoire associative : adressable par le contenu (1 clé <=> 1 contenu); recherche de la présence de l’information dans la mémoire en 1 seul cycle ;
Avantages : Rapidité (Exemple : mémoire cache du processeur)
RAID : Redundant Array of Inexpensive / Independent Disk
Le RAID peut être géré de deux façons :
Par voie
logicielle, la partition système ne peut bénéficier
du mode RAID puisque c'est elle qui le gère (à
l'exception du mode Mirroir "RAID1").
Avantages : peu
cher, souple, compatible.
Inconvénients :
consommateur de CPU ; pas en partition système.
Par voie
matérielle, le système est plus rapide et devient
transparent pour le système d'exploitation dont la partition
peut ainsi être intégré dans le
RAID.
Avantages : détection des défauts,
le remplacement à chaud des unités défectueuses
et offrent la possibilité de reconstruire de manière
transparente les disques défaillants ; peu consommateur
de CPU.
Inconvénients : compatibilité ;
souplesse d’administration et d’évolution.
Les techniques :
La concaténation : nombre quelconque de volume bout à bout pour présenter 1 seul volume logique (peu fiable : 1 panne tout en panne)
Agrégation par bandes (stripping) : concaténation mais en découpant préalablement en bandes de taille fixe un nombre quelconque de volume de données de taille identique. On alterne alors une bande de chaque volume pour créer le "volume agrégé par bandes".
Le miroitage (mirroring) : plusieurs unités de stockage de données pour stocker des données identiques sur chacune (cher ; fiable ; pas d’augmentation des performances)
Redondance par calcul de parité : consiste à déterminer si sur n bits de données considérés, le nombre de bits à l'état 1 est pair ou impair (RAID 5)
Avantages :
Augmenter la capacité, grâce aux agrégats de partitions qui permettent de créer des partitions s'étendant sur plusieurs disques.
Améliorer les performances, grâce au « striping » qui permet de lire et d'écrire sur plusieurs disques simultanément pour en augmenter le débit. (voir RAID 0).
Apporter la tolérance de panne, on se prémunit ainsi contre les défaillances disque.
Raid 0 :

Figure 22 : Raid 0
Appelé aussi Striping, les données sont réparties sur au moins deux disques sous la forme d'agrégats par bandes.
Cette méthode de
gestion des disques améliore uniquement la vitesse en
lecture et en écriture. Le débit de la grappe de
disque en RAID 0 est égal au débit d'un disque
multiplié par le nombre de disque. Elle n'apporte aucune
sécurité des données, la perte d'un disque
entraîne la perte des données de tous les disques de la
grappe.
Ce mode est recommandé pour la production d'image, de vidéo.
Raid 1 :

Figure 22 : Raid 1
Appelé aussi
"Mirroring ou Duplexing". Le Mirroring utilise un
seul contrôleur pour tous les disques, alors que le duplexing
utilise un contrôleur par disque ce qui permet de tolérer
la panne d'un contrôleur.
Ce système accroît
la sécurité des données par duplication d'un
disque sur un autre. Il améliore les performances en
lecture par accès simultanés aux 2 disques.
Et correspond au Mode Miroir de Windows NT4 Server. Ce mode est recommandé pour les serveurs de Mails.
Raid 5 :

Figure 22 : Raid 5
Le "disque de
contrôle" est réparti entre tous les disques, ce
qui élimine le goulot d'étranglement du RAID 4.
Les
disques travaillent tous autant. Si les disques sont compatibles, le
"HotPlug" peut être utilisé, ce mode
permet l'échange de disques à chaud. Il améliore
la vitesse en lecture et en écriture.
Ce mode
correspond à l'agrégat par bandes avec parité
sous NT4 Server. Ce mode est recommandé pour les serveurs
de fichiers, d'applications, de base de données, Web.
Comparatif :
|
Niveau |
Avantages |
Inconvénients |
|
RAID 0 |
|
|
|
RAID 1 |
|
|
|
RAID 3 |
|
|
|
RAID 5 |
|
|
Attention : un RAID 5 n'est pas forcément mieux qu'un RAID 0, 1 ou 3, tout dépend de l'utilisation et du but recherché.
La transmission de l’information se caractérise par :
Un délai de paquétisation
Un délai de transport
Un délai de présentation
En anglais jitter ; La gigue est la variation dans le délai de transmission ; variation du signal numérique dans le temps ou en phase.
Pour maintenir une stabilité minimale et éviter les ruptures de débit, il convient de placer une mémoire tampon ou cache en réception ; son rôle est d’assurer une indépendance minimale du débit de sortie par rapport au débit d’entrée. Une autre solution est l’insertion d’un temps de garde.
Latence, délai ou temps de réponse (en anglais delay) : elle caractérise le retard entre l'émission et la réception d'un paquet.
La liaison half-duplex (parfois appelée liaison à l'alternat ou semi-duplex) caractérise une liaison dans laquelle les données circulent dans un sens ou l'autre, mais pas les deux simultanément.
La liaison full-duplex (appelée aussi duplex intégral) caractérise une liaison dans laquelle les données circulent de façon bidirectionnelle et simultanément.
Une interruption
est utilisée pour gérer des événements
provenant de l'extérieur (clavier, souris, carte, ...)
alors qu'une exception est utilisée pour gérer des
erreurs dans le programme comme des divisions par zéro. Le
traitement déclenché produit une conséquence
identique dans les 2 cas : l'interruption du flot normal du programme
et la redirection vers une routine de traitement de cette
interruption/exception.
Au niveau interne, une
interruption est gérée par le processeur une fois
l'instruction courante terminée. Si le processeur reçoit
un signal sur sa broche d'interruption, il va rechercher l'adresse de
la routine de traitement de cette interruption dans la table des
interruptions, et transmettre le contrôle du programme à
cette routine. Une fois celle ci terminée, le processeur va
continuer l'exécution du programme à l'endroit où
il a été stoppé par l'interruption.
En
ce qui concerne les exceptions, il en existe 3 sortes :
- les
Faults : elles sont détectées et gérées
par le processeur avant les instructions ayant provoqué
la Fault
- les Traps (déroutement) : à
l'inverse des faults, elles sont gérées par le
processeur après exécution de l'instruction
ayant causé la Trap. Les interruptions définies par
l'utilisateur entrent également dans cette catégorie.
- les Aborts : utilisées uniquement pour signaler
de graves problèmes systèmes, lorsque plus aucune
opération n'est possible.
Une machine est multiprogrammé si plusieurs programmes sont chargés en mémoire dans le but de partager le CPU et de mettre à profit les "temps morts" d'un programme (par exemple les opérations d'entrée-sortie) pour "faire avancer" les autres programmes.
La multiprogrammation implique la nécessité de partager la mémoire de l'ordinateur entre plusieurs programmes, et de protéger la mémoire allouée à chacun d'eux des éventuels accès intempestifs des autres. Ceci a conduit au développement des techniques de partage de la mémoire : mémoire partitionnée, segmentée, paginée, mémoire virtuelle etc.
Le taux de multiprogrammation est le nombre de processus présents dans la mémoire d'un ordinateur à un instant donné.
La mémoire centrale est découpée en deux parties :
Image du noyau du système d’exploitation : composé de son code exécutable et ses structures de données
Reste de la RAM géré par la mémoire virtuelle :
Pour satisfaire les demandes du noyau en tampons, descripteurs et autre structures de données dynamiques du noyau.
Pour satisfaire les requêtes des processus en zones mémoire générique et en mappage de fichiers.
Pour obtenir de meilleurs performances des disques et autres périphériques utilisant des tampons par le biais des caches.
La mémoire virtuelle est une couche logique entre les requêtes des applications concernant la mémoire et l’unité matérielle de gestion de la mémoire (MMU).
La mémoire virtuelle garantie un adressage linéaire de la mémoire alors qu’en réalité les pages physiques peuvent ne pas être contiguës ou non présente en mémoire centrale.
Avantages :
exécution de plusieurs processus en même temps
plus de processus
plus de mémoire par processus
exécution de processus dont le code n’est que partiellement chargé en mémoire
chargement des pages à la demande.
Les processus peuvent partager une image mémoire unique d’un programme ou d’une librairie
Les programmes peuvent être relogé, placer n’importe où dans la mémoire
Inconvénients :
erreur de défaut de page
contrainte de programmation (performance de l’accès en mémoire)
Memory Management Unit : matériel responsable de l'accès à la mémoire demandée par le microprocesseur.
La pagination à la demande (demand paging) : si le processus adresse une donnée non présente en mémoire centrale, il génère une exception (fault page ; erreur de pagination). Alors le gestionnaire de la mémoire (MMU) trouve et affecte une zone mémoire physique (une page) au processus puis il initialise les données de la page pour le processus.
La copie à l’écriture (Copy On Write) : tant que les processus utilisent des données identiques sans les modifier, le gestionnaire de mémoire physique leur donne une référence en mémoire identique. Mais dès lors qu’un programme modifie une partie de données identiques, le gestionnaire de mémoire crée une copie des données initiales pour chaque processus.
Un progiciel est un logiciel commercial vendu par un éditeur sous forme d'un produit complet, plus ou moins clés en main.
Un progiciel comprend :
les composants logiciels (par exemple sous forme de CD-ROM) ;
une documentation en ligne et (ou) imprimée ;
des stages de formation ;
éventuellement une assistance à l'installation, au paramétrage et à la mise en œuvre ;
éventuellement une assistance téléphonique ;
Un processus est une tâche en train de s'exécuter. On appelle processus l'image de l'état du processeur et de la mémoire au cours de l'exécution d'un programme
Un processus (en anglais, process), est défini par :
un ensemble d'instructions à exécuter (un programme) ;
un espace mémoire pour les données de travail ;
éventuellement, d'autres ressources, comme des descripteurs de fichiers, des ports réseau, etc.
Les différents états d’un processus sont : en cours d’exécution (élu), prêt à être exécuté et bloqué. Si le système d’exploitation utilise un swap, les processus peuvent aussi prendre les état prêt à être exécuter et bloqué dans le swap.

Figure 22 : Les différents états d'un processus
Un processus est l’entité active élémentaire d’un système UNIX. C’est un programme + un contexte. Un processus est implémenté sous la forme d’une entrée dans une table à laquelle est associée une structure définissant toutes les ressources utilisées par le processus.

Figure 22 : Les différents états d'un processus UNIX
Dans un système Unix, c’est un processus qui s’exécute en permanence, en tache de fond. Aucun terminal ne lui est rattaché.
Il est créé à partir des fichiers de démarrage (/etc/init.d/rc) ou à partir d’une crontab. Tous ses descripteurs de fichier sont fermés (entrée standard, sortie standard et erreur) et son répertoire est un répertoire racine.
La principale différence entre un programme qui s’exécute en mode noyau et en mode utilisateur est que le mode noyau à un accès privilégié :
aux instructions du processeur,
à la mémoire,
aux données du système d’exploitation
et aux périphériques.
Les applications fonctionnent en mode utilisateurs et le système d’exploitation en mode noyau.
Les applications n’ont pas un accès direct aux périphériques, à la mémoire et aux données du système et ne peuvent pas ainsi les corromprent.
Une commutation de contexte (context switch) consiste à sauvegarder l'état d'un processus et à restaurer l'état d'un autre processus de façon à ce que des processus multiples puissent partager les ressources d'un seul processeur dans le cadre d'un système d'exploitation multitâche.
Une commutation de contexte peut être plus ou moins coûteuse en temps processeur suivant le système d'exploitation et l'architecture matérielle utilisés.
Le contexte sauvegardé doit au minimum inclure une portion notable de l'état du processeur (registres généraux, registres d'états, etc.) ainsi que, pour certains systèmes, les données nécessaires au système d'exploitation pour gérer ce processus.
La commutation de contexte invoque au moins trois étapes. Par exemple, en présumant que l'on veut commuter l'utilisation du processeur par le processus P1 vers le processus P2 :
Sauvegarder le contexte du processus P1 quelque part en mémoire (usuellement sur la pile de P1).
Retrouver le contexte de P2 en mémoire (usuellement sur la pile de P2).
Restaurer le contexte de P2 dans le processeur, la dernière étape de la restauration consistant à reprendre l'exécution de P2 à son point de dernière exécution.
Certains processeurs peuvent sauvegarder et restaurer le contexte du processeur en interne, évitant ainsi d'avoir à sauvegarder ce contexte en mémoire vive.
L’espace d’adressage d’un processus contient toutes les zones d’adresse de la mémoire virtuelle qu’un processus est autorisé à référencer.
Il contient :
Le code exécutable du programme (Text)
Le code exécutable et les données des librairies utilisés par le programme (en statique et les références en dynamique)
Les données initialisées du programme (DS)
Les données non initialisées du programme (CS)
La pile initiale du programme (pile en mode utilisateur et pile en mode noyau)
Le tas, soit la mémoire allouée dynamiquement par et pour le programme
Un processus léger (thread), également appelé fil d'exécution, est similaire à un processus car tous deux représentent l'exécution d'un ensemble d'instructions du langage machine d'un processeur. Du point de vue de l'utilisateur, ces exécutions semblent se dérouler en parallèle. Toutefois, là où chaque processus possède sa propre mémoire virtuelle, les processus légers appartenant au même processus père et ils se partagent sa mémoire virtuelle. Par contre, tous les processus légers possèdent leur propre pile système.
Inconvénients :
coût de la commutation de contexte
besoin de synchronisation (utilisation de sémaphores)
Pipe : tube anonyme ou tube nommé (fifo) par système de fichier
Msq : message queue ; communication asynchrone par mémoire centrale
Socket : communication synchrone et/ou asynchrone par réseau
Tableau récapitulatif de l'implémentation de la synchronisation pour les processus lourds et les processus légers.
|
Type |
processus lourd, fork wait |
processus lourd, sémaphore IPC |
processus lourd, tube |
processus lourd, message IPC |
processus lourd, segment partagé |
Java Thread |
|
Système de nommage |
PID / getPId |
cle IPC |
interne |
cle IPC |
cle IPC |
les objets |
|
nombre d'activités |
2 |
N |
2 |
N |
N |
N |
|
appel bloquant |
wait() |
p() |
read() |
receive() |
Non |
syncronized/wait() |
|
Communication |
exit(p) |
Non |
stream |
message |
taille du segment |
les objets |
|
volume de la communication |
2 octets |
Non |
non limité |
taille de la boite aux lettres |
non limité |
Machine virtuelle |
La famine est un problème que peut avoir un algorithme d'exclusion mutuelle. Il se produit lorsqu'un algorithme n'est pas équitable, c'est-à-dire qu'il ne garantit pas à tous les threads souhaitant accéder à une section critique une probabilité non nulle d'y parvenir en un temps fini.
Un interblocage (deadlock) est un phénomène qui peut survenir en programmation concurrente et qui se produit lorsque deux processus légers (thread) concurrents s'attendent mutuellement. Les processus bloqués dans cet état le sont définitivement, il s'agit donc d'une situation catastrophique.
Il n'existe aucune solution permettant d'éviter tous les interblocages. Il est par contre possible de prendre des mesures pour limiter le risque d'interblocage, à commencer par une analyse très précise de l'application à écrire.
Une méthode consiste à toujours acquérir les mutex (exclusion mutuelle) dans le même ordre. En effet, si plusieurs processus légers (thread) nécessitent d'acquérir plusieurs verrous pour effectuer leur travail, s'ils acquièrent les verrous dans un ordre différent, il est possible qu'ils se bloquent lors de la séquence d'acquisition.
Il convient aussi de s'intéresser aux priorités des processus. En effet, si par exemple un processus de haute priorité utilise un verrou en commun avec un processus de basse priorité (voir aussi inversion de priorité), il est possible d'obtenir des situations de blocage. Une solution à ce genre de problème consiste à n'utiliser des verrous qu'entre des processus de même priorité.
C’est une variable protégée qui constitue une méthode utilisée couramment pour restreindre l'accès à des ressources partagées (par exemple un espace de stockage) dans un environnement de programmation concurrente. Sa protection consiste à pouvoir être testé et modifié au cours d'un cycle insécable (masquage des interruptions pendant l’accès au sémaphore).
Les trois opérations prises en charge sont Init, P et V. Elles signifient tester, et incrémenter (en français "Puis-je?" et "Vas-y!"). La valeur d'un sémaphore est le nombre d'unités de ressource (exemple : imprimantes...) libres ; s'il n'y a qu'une ressource, un sémaphore à système numérique binaire avec les valeurs 0 ou 1 est utilisé.

Figure 22 : Les opérations sur un sémaphore
Le sémaphore SEM, sa liste L et son compteur K, SEM sont accessibles aux opérations:
INIT(SEM, VAL)
P(SEM)
V(SEM)
Pour éviter l'attente, un sémaphore peut avoir une file de processus associée (généralement une file du type FIFO). Si un processus exécute l'opération P sur un sémaphore qui a la valeur zéro, le processus est ajouté à la file du sémaphore. Quand un autre processus incrémente le sémaphore en exécutant l'opération V, et qu'il y a des processus dans la file, l'un d'eux est retiré de la file et reprend la suite de son exécution.
Les producteurs/consommateurs
Les lecteurs/rédacteurs
Le dîner des philosophes
Un Mutex (Exclusion mutuelle) est une primitive de synchronisation utilisée en programmation pour éviter que des ressources partagées d'un système ne soient utilisées en même temps.
Un Mutex est un sémaphore initialisé à 1.
L'inversion de priorité est un phénomène qui peut se produire en programmation concurrente. Il s'agit d'une situation dans laquelle un processus de haute priorité ne peut pas avoir accès au processeur car il est utilisé par un processus de plus faible priorité.
Phénomène qui se produit lorsque des processus utilisent des ressources partagées protégées par des sémaphores communs.
Solutions : Il n'existe pas de solution simple permettant d'éviter toutes les inversions de priorité. Il est néanmoins possible de prendre des mesures pour limiter ces risques. En particulier, il est possible de
N'autoriser l'accès à des sections critiques qu'à des threads de même priorité.
Utiliser des sémaphores adaptés, par exemple des sémaphores à héritage de priorité ou des sémaphores à priorité plafond.
Un signal est une interruption logicielle émise vers un processus pour lui indiquer l’arrivée d’un événement attendu ou non. L’émetteur d’un signal ne peut pas connaître l’attitude adoptée par le destinataire, en particulier si celui-ci a décidé d’ignorer l’arrivée du signal, l’émetteur n’en saura rien.
Les signaux peuvent être envoyés :
d’un processus à un autre : on utilise alors l’appel système kill() ;
par le noyau à un processus : pour indiquer, par exemple, une erreur fatale qui provoquera l’arrêt du processus
Ensemble de logiciels exécutés sur un ordinateur exploitant l’ordinateur afin d’offrir aux programmes des services et aux programmeurs un accès simplifiés aux ressources de la machine.
Un système d’exploitation est spécifique à une famille de processeur (exemple : x86)
Il gère :
la mémoire
les entrées/sorties
les interruptions et le processeur
les fichiers
les processus
Unix
Windows
MacOS
Netware de Novell
Avantages :
Libère l’utilisateur de tout problème d’exploitation qui ne se soucie que de la mise au point de ses programmes. Le reste de l’administration étant du ressort de l’administrateur système
Solution simple aux partages d’informations entre les usagers.
Transparence de l’architecture matérielle
Inconvénients :
Très sensibles aux variations de charge
Difficile d’adapter une configuration donnée aux besoins immédiats
Sensible aux pannes, indisponibilité du système sur changement d’un équipement
Coût financier élevé
Un système distribué est un ensemble de station de travail utilisable simultanément par des usagers. Chaque station possèdent son système d’exploitation et est reliée aux autres pour permettre l’échange d’information. C’est l’aspect communication qui fait son point faible et son point fort.
Avantages :
Hétérogénéité des systèmes : plusieurs machines de nature différente (calculateur vectoriel, gestionnaire de fichier, poste de travail)
Croissance modulaire
Grande disponibilité : possibilité d’arrêter un élément de l’architecture sans arrêt complet
Inconvénients :
Absence d’état globale
Le partage d’information : pas de mémoire commune ; données répliquées pour plus de disponibilité entraîne une politique de mise à jour complexe ;
Administration système difficile : cohérence entre administrateurs systèmes localisés sur des sites différents.
Une architecture client serveur est un système composé de deux programmes, un client et un serveur, pouvant être exécuté sur un même ordinateur ou sur deux ordinateurs distant. Les deux programmes communique généralement par une interface réseau.
Le client est une entité qui demande l’accès à un service ou à une ressource.
Le serveur est une entité qui rend le service ou qui attribue la ressource. A chaque serveur est associé une adresse de service. En réseau il s’agit d’un numéro de port (entier de 0 à 65535). Un serveur se caractérise par son interface qui spécifie les services qu’il fournit et leur mode d’utilisation. Il existe deux types de processus serveurs :
Les serveurs itératifs : le processus traite lui-même la réponse. Ce type de serveur est utilisable lorsque le temps de traitement est très court, ou si 1 seul client utilise le serveur.
Les serveurs parallèles : le processus invoque un autre processus pour traiter la requête du client. Ce processus est crée par l’appelle système fork() ; le processus père ne se bloque pas sur la fin de l’exécution de son fils et peut ainsi se remettre en attente d’autres requêtes.
Il existe deux types de serveur selon les traitements réalisés :
Les serveurs sans états (state less) : ne conservent aucune information sur les clients
Les serveurs avec état (state full) : conservent des informations sur l’état de ces clients après chaque requête.
En cas de rupture de la communication, les reprises sont plus ou moins simples avec les serveurs sans état mais peuvent donner lieu parfois à des fonctionnements aléatoires.
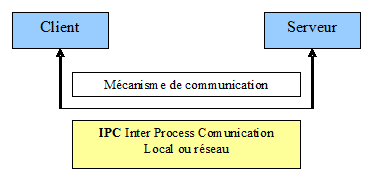
Figure 22 : Architecture Client/Serveur
L'architecture 3-tier (de l'anglais tier signifiant étage ou niveau) est un modèle logique d'architecture applicative qui vise à séparer très nettement trois couches logicielles au sein d'une même application ou système, à modéliser et présenter cette application comme un empilement de trois couches, étages, niveaux ou strates dont le rôle est clairement défini :
la présentation des données : correspondant à l'affichage, la restitution sur le poste de travail, le dialogue avec l'utilisateur ;
le traitement métier des données : correspondant à la mise en œuvre de l'ensemble des règles de gestion et de la logique applicative ;
et enfin l'accès aux données persistantes (persistancy en anglais) : correspondant aux données qui sont destinées à être conservées sur la durée, voire de manière définitive.
Dans cette approche, les couches communiquent entre elles au travers d'un « modèle d'échange », et chacune d'entre elles propose un ensemble de services rendus. Les services d'une couche sont mis à disposition de la couche supérieure. On s'interdit par conséquent qu'une couche invoque les services d'une couche plus basse que la couche immédiatement inférieure ou plus haute que la couche immédiatement supérieure (chaque niveau ne communique qu'avec ses voisins immédiats).
Le rôle de chacune des couches et leur interface de communication étant bien définis, les fonctionnalités de chacune d'entre elles peuvent évoluer sans induire de changement dans les autres couches. Cependant, une nouvelle fonctionnalité de l'application peut avoir des répercussions dans plusieurs d'entre elles. Il est donc essentiel de définir un modèle d'échange assez souple, pour permettre une maintenance aisée de l'application.
Ce modèle d'architecture 3-tier a pour objectif de répondre aux préoccupations suivantes :
allégement du poste de travail client (notamment vis-à-vis des architectures classiques client-serveur de données –- typiques des applications dans un contexte Oracle/Unix) ;
prise en compte de l'hétérogénéité des plates-formes (serveurs, clients, langages, etc.) ;
introduction de clients dits « légers » (plus liée aux technologies Intranet/HTML qu'au 3-tier proprement dit) ;
et enfin, meilleure répartition de la charge entre différents serveurs d'application.
Précédemment, dans les architectures client-serveur classiques, les couches présentation et traitement étaient trop souvent imbriquées. Ce qui posait des problèmes à chaque fois que l'on voulait modifier l'IHM du système.
L'activation à distance (entre la station et le serveur d'application) des objets et de leurs méthodes (on parle d'invocation) peut se faire au travers d'un ORB (avec le protocole IIOP ou au moyen des technologies COM/DCOM de Microsoft ou encore avec RMI en technologie J2EE). Cette architecture ouverte permet également de répartir les objets sur différents serveurs d'application (soit pour prendre en compte un existant hétérogène, soit pour optimiser la charge).
Il s'agit d'une architecture logique qui se répartit ensuite selon une architecture technique sur différentes machines physiques, bien souvent au nombre de 3, 4 ou plus. Une répartition de la charge doit dans ce cas être mise en place.
Logiciel qui interprète les instructions d’un programme.
Avantages : facilement portable (indépendant de l’OS)
Inconvénients : lent
Un ramasse-miettes, ou récupérateur de mémoire, ou glaneur de cellules (en anglais garbage collector, abrégé en GC) est un sous-système informatique de gestion automatique de la mémoire. Il est responsable du recyclage de la mémoire préalablement allouée puis inutilisée.
Le principe de base de la récupération automatique de la mémoire est simple :
déterminer quels objets dans le programme ne peuvent pas être utilisés,
récupérer le stockage utilisé par ces objets.
Bien qu'en général il soit impossible de déterminer à l'avance à quel moment un objet ne sera plus utilisé, il est possible de le découvrir à l'exécution : un objet sur lequel le programme ne maintient plus de référence, donc devenu inaccessible, ne sera plus utilisé.
Les ramasse-miettes utilisent un critère d'accessibilité pour déterminer si un objet peut être potentiellement utilisé.
Les principes sont :
un ensemble distinct d'objets qui sont supposés atteignables, ce sont les racines. Dans un système typique ces objets sont les registres machine, la pile, le pointeur d'instruction, les variables globales. En d'autres termes tout ce qu'un programme peut atteindre directement.
tout objet référencé depuis un objet atteignable est lui-même atteignable.
Dit autrement : un objet atteignable peut être obtenu en suivant une chaîne de pointeurs ou de références.
Bien évidemment, un tel algorithme est une approximation conservatrice de l'objectif idéal de destruction des valeurs ne servant plus : certaines valeurs peuvent fort bien être accessibles depuis les racines mais ne plus jamais être utilisées. Cet objectif idéal est cependant inaccessible algorithmiquement : déterminer quelles valeurs serviront dans le futur est équivalent au problème de l'arrêt.
Cette approximation conservatrice est la raison de la possibilité de fuites de mémoire, c'est-à-dire de l'accumulation de blocs de mémoire qui ne seront jamais réutilisés, mais jamais libérés non plus. Par exemple, un programme peut conserver un pointeur sur une structure de donnée qui ne sera jamais réutilisée. Il est pour cette raison recommandé d'écraser les pointeurs vers des structures inutilisées, afin d'éviter de conserver des références inutiles.
L'algorithme du ramasse-miettes est dû à Schorr et Waite. Les ramasse-miettes effectuent des cycles de ramassage. Un cycle est démarré lorsque le récupérateur décide (ou est notifié) qu'il doit récupérer de l'espace de stockage. Un cycle est constitué des étapes suivantes :
Créer des ensembles dits noir, gris et blanc. Initialement, l'ensemble noir est vide, l'ensemble gris contient les objets « racines » et éventuellement certains objets supplémentaires choisis en fonction de l'algorithme particulier employé, et l'ensemble blanc contient tout le reste. À tout moment dans l'exécution de l'algorithme, un objet ne peut être que dans un seul des trois ensembles. L'ensemble blanc peut être vu comme l'ensemble des objets dont nous essayons de récupérer l'espace mémoire ; au cours du cycle, l'algorithme ôtera des objets de l'ensemble blanc, y laissant les objets dont il peut réclamer l'espace mémoire.
Choisir un objet de l'ensemble gris, déplacer cet objet vers l'ensemble noir, déplacer tous les objets blancs référencés directement par cet objet vers l'ensemble gris. Cette étape est répétée jusqu'à ce qu'il n'y ait plus d'objets dans l'ensemble gris.
Quand il n'y a plus d'objets dans l'ensemble gris, alors tous les objets restant dans l'ensemble blanc ne sont pas atteignables, et l'espace mémoire qu'ils utilisent peut être réclamé.
L'invariant des trois couleurs peut être traduit comme ceci : aucun objet noir ne pointe directement sur un objet blanc.
L'algorithme de base à plusieurs variantes.
Les ramasse-miettes qui déplacent les objets en mémoire (qui changent leur adresse), dits stop and copy.
Certains récupérateurs peuvent correctement identifier toutes les références à un objet : ils sont appelés des récupérateurs « exacts », par opposition avec des récupérateurs « conservateurs » ou « partiellement conservateurs ». Les ramasse-miettes « conservateurs » doivent présumer que n'importe quel suite de bits en mémoire est un pointeur si (lorsqu'ils sont interprétées comme un pointeur) il pointe sur un quelconque objet instancié. Ainsi, les récupérateurs conservateurs peuvent avoir des faux négatifs, où l'espace mémoire n'est pas réclamé à cause des faux pointeurs accidentels. En pratique ceci est rarement un gros inconvénient.
Le ramasse-miettes peut s'exécuter en alternance ou en parallèle avec le reste du système ; les récupérateurs les plus simples suspendent l'exécution du système lorsqu'ils exécutent un cycle ; ils ne sont pas incrémentaux ; les récupérateurs incrémentaux entrelacent leur travail pour s'exécuter pendant les temps d'inactivité du reste du système. Certains récupérateurs incrémentaux peuvent s'exécuter complètement en parallèle dans un thread séparé ; ils peuvent en théorie s'exécuter sur un processeur différent, mais le coût de la mise en cohérence des caches rend cette approche moins pratique qu'il n'y paraît.
Classification :
Marquage et nettoyage
Ou mark and sweep en anglais. Un ramasse-miettes de ce type maintient un bit (ou deux) associé à chaque objet pour indiquer s'il est blanc ou noir ; l'ensemble gris est maintenu soit comme une liste séparée ou en utilisant un autre bit. Un récupérateur copieur distingue les objets gris et noirs en les copiant vers d'autres zones mémoire (l'espace de copie) et souvent différencie les objets noirs des objets gris en bi-partitionnant l'espace de copie (dans le cas le plus simple en maintenant un unique pointeur qui indique la séparation entre les objets noirs et gris). Un avantage des ramasse-miettes copieurs est que la libération des objets blancs (morts) se fait en vrac, en libérant en une seule fois la zone ancienne, et que le coût du ramasse-miettes est proportionnel aux nombres d'objets vivants. Ceci est particulièrement utile quand il y a beaucoup d'objets alloués, dont la plupart sont temporaires et meurent rapidement.
Ou conservative vs precise en anglais. Un ramasse-miettes est conservatif lorsqu'il ne libère pas certaines zones de mémoire devenues inutiles. Par exemple, le ramasse-miettes de Boehm considère tout mot mémoire comme un pointeur potentiel à suivre, y compris sur la pile d'appel, et s'utilise facilement en C. Au contraire, les ramasse-miettes précis distinguent partout les pointeurs des autres données (y compris sur la pile d'appel) et nécessitent pour ce faire la coopération du compilateur (qui va génèrer les descripteurs de cadre d'appels) ou du programmeur. Généralement, les ramasse-miettes conservatifs sont marqueurs et ne modifient pas l'adresse des zones utilisées.
Ou generational GC en anglais. Toutes les données d'un programme n'ont pas la même durée de vie. Certaines sont éliminables très peu de temps après leur création (par exemple, une structure de donnée créée uniquement pour retourner une valeur d'une fonction, et démantelée dès que les données en ont été extraites). D'autres persistent pendant toute la durée d'exécution du programme (par exemple, des tables globales créées pendant l'initialisation). Un ramasse-miettes traitant toutes ces données de la même façon n'est pas forcément des plus efficaces.
Une solution serait de demander au programmeur d'étiqueter les données créées selon leur durée de vie probable. Cependant, cette solution serait lourde à utiliser ; par exemple, il est courant que les données soient créées dans des fonctions de bibliothèque (par exemple, une fonction créant une table de hachage), il faudrait leur fournir les durées de vie en paramètre.
Une méthode moins invasive est le système des générations. Le ramasse-miettes opère alors sur une hiérarchie de 2 ou plus générations, étagées de la plus « jeune » à la plus « âgée ». Les données nouvellement créées sont (en général) placées dans la génération la plus jeune. On ramasse assez fréquemment les miettes dans cette génération jeune ; les données encore présentes à l'issue de la destruction des données inaccessibles de cette génération sont placées dans la génération d'âge supérieur, et ainsi de suite. L'idée est que les données de plus courte durée de vie n'atteignent, pour la plupart, pas la génération supérieure (elle peuvent l'atteindre si elles viennent d'être allouées quand le ramassage de miettes les repère dans la génération jeune, mais c'est un cas rare).
On utilise généralement 2 ou 3 générations, de tailles croissantes. Généralement, on n'utilise pas le même algorithme de ramasse-miettes pour les diverses générations. Il est ainsi courant d'utiliser un algorithme non incrémental pour la génération la plus jeune : en raison de sa faible taille, le temps de ramasse-miettes est faible et l'interruption momentanée de l'exécution de l'application n'est pas gênante, même pour une application interactive. Les générations plus anciennes sont plutôt ramassées avec des algorithmes incrémentaux.
Le réglage des paramètres d'un ramasse-miettes à génération peut être délicat. Ainsi, la taille de la génération la plus jeune peut influencer de façon importante le temps de calcul (un surcoût de 25%, par exemple, pour une valeur mal choisie) : temps de ramasse-miettes, impact sur la localité du cache... Par ailleurs, le meilleur choix dépend de l'application, du type de processeur et d'architecture mémoire.
Une solution qui vient vite à l'esprit pour la libération automatique de zones de mémoire est d'associer à chacune un compteur donnant le nombre de références qui pointent sur elle. Ces compteurs doivent être mis à jour à chaque fois qu'une référence est créée, alterée ou détruite. Lorsque le compteur associé à une zone mémoire atteint zéro, la zone peut être libérée.
Cette technique souffre d'un inconvénient certain lors de l'usage de structures cycliques : si une structure A pointe sur une structure B qui pointe sur A (ou, plus généralement, s'il existe un cycle dans le graphe des références), mais qu'aucun pointeur extérieur ne pointe ni sur A ni sur B, les structures A et B ne sont jamais libérées : leurs compteurs de références sont strictement supérieurs à zéro (et comme il est impossible que le programme accèdent à A ou B, ces compteurs ne peuvent jamais repasser à zéro).
En raison de ces limites, certains considèrent que le comptage de références n'est pas une technique de récupération de mémoire à proprement parler ; ils restreignent le terme de récupération de mémoire à des techniques basées sur l'accessibilité.
Le comptage de références souffre de certains problèmes sérieux, comme son coût élevé en temps de calcul et aussi en espace mémoire et, comme on l'a vu, l'impossibilité de gérer les références circulaires. D'un autre côté, il récupère les « miettes » plutôt vite, ce qui présente des avantages s'il y a des destructeurs à exécuter pour libérer les ressources rares (sockets...) autres que le tas (mémoire).
Des systèmes hybrides utilisant le comptage de références pour obtenir la libération quasi immédiate des ressources, et appelant à l'occasion un récupérateur de type Mark and Sweep pour libérer les objets contenant des cycles de références, ont été proposés et parfois implémentés. Cela donne le meilleur des deux mondes, mais toujours au prix d'un coût élevé en termes de performances.
Avantages et inconvénients
Les langages utilisant un ramasse-miettes permettent d'écrire des programmes plus simples et plus sûrs. La mémoire étant gérée automatiquement par l'environnement d'exécution, le programmeur est libéré de cette tâche, source de nombreuses erreurs difficiles à débusquer. La gestion manuelle de la mémoire est l'une des sources les plus courantes d'erreur.
Trois types principaux d'erreurs peuvent se produire :
l'accès à une zone non allouée, ou qui a été libérée,
la libération d'une zone déjà libérée,
la non-libération de la mémoire inutilisée (fuites mémoire).
L'utilisation d'outils et de méthodologie appropriés permet d'en réduire l'impact, tandis que l'utilisation d'un ramasse-miettes permet de les éliminer presque complètement – les fuites de mémoire restent possibles, bien que plus rares. Cette simplification du travail de programmation peut présenter quelques inconvénients, principalement au niveau des performances des programmes les utilisant.
Des mesures montrent que dans certains cas l'implémentation d'un ramasse-miettes augmente les performances d'un programme, dans d'autre cas le contraire se produit. Le choix des paramètres du ramasse-miettes peut aussi altérer ou améliorer significativement les performances d'un programme. Lorsque le ramasse-miettes effectue de nombreuses opérations de copies en tâche de fond (cas de l'algorithme stop-and-copy), il tend à défragmenter la mémoire. Le ramasse-miettes peut ainsi se révéler plus rapide qu'un codage ad-hoc de l'allocation/désallocation. Les meilleures implémentations peuvent aussi optimiser l'utilisation des caches mémoires, accélérant ainsi l'accès aux données. A contrario, l'opération de collection est souvent coûteuse.
Il est difficile de borner le temps d'exécution de la phase de collection des objets non atteignables. L'utilisation d'un ramasse-miettes standard peut donc rendre difficile l'écriture de programmes temps réel ; un ramasse-miettes spécialisé (temps-réel) doit être utilisé pour cela.
Sans intervention du programmeur, un programme utilisant un ramasse-miettes a tendance à utiliser plus de mémoire qu'un programme où la gestion est manuelle (en admettant que, dans ce cas, il n'y a pas de fuites, d'erreur d'accès ou de libération). Toutefois, rien n'interdit d'employer des stratégies de pré-allocation des objets utilisés, dans des pools, lorsqu'on veut minimiser le taux d'allocation/désallocation. Dans ce cas, le ramasse-miettes fournit toujours le bénéfice d'une programmation sans erreur grave de gestion de la mémoire (une assurance).
Bien que ce ne soit pas le but d'un ramasse-miettes son implémentation peut aussi faciliter l'implémentation de la persistance d'objet (certains algorithmes sont partagés).
A identifier la partie de l'adresse représentant le réseau. Ce masque est composé de 32 bits: les bits représentant le réseau sont positionné à 1.
A identifier la partie adresse représentant des sous- réseaux (subnet, ou segment logique, ou segment IP) destinés à créer des structures logiques au niveau du réseau d'entreprise.
Exemple : mask = 255.255.0.0 pour un réseau de class B 155.1.54.0
Si le premier bit est à 0, il s'agit d'une classe A (en décimal de 1.0.0.0 à 127.0.0.0)
Si les 2 premiers bits sont à 1 0, il s'agit d'une classe B (en décimal de 128.0.0.0 à 191.0.0.0).
Si les 3 premiers bits sont 1 1 0, il s'agit d'une classe C (en décimal de 192.0.0.0 à 254.0.0.0).
Une adresse Ethernet, aussi appelé adresse MAC (Media Access Control) ou adresse physique, est un identifiant unique géré par un organisme international et associé à une carte réseau par son constructeur. Cette adresse permet d’identifier la carte réseau sur un réseau Ethernet.
Elle se compose de 8 octets en hexadécimal (exemple : 00-1B-77-B9-1F-AA)
C’est une adresse qui permet d’adresser toutes les machines d’un même réseau. Elle est généralement obtenue en positionnant à 1 tous les bits correspondants à la partie adresse d’un réseau.
Exemple : pour un réseau de classe C avec comme adresse 192.168.1.0 et comme masque 255.255.255.0, l’adresse de diffusion est 192.168.1.255
Etoile : nœud central qui supporte toute la charge ; un équipement, concentrateur ou Hub, connecte toutes les stations entre elles ; Si le concentrateur tombe en panne le réseau ne fonctionne plus, par contre une station peut être retiré sans planter le réseau.
Bus : réseau à diffusion ; l'information passe 'devant' chaque noeud et s'en va 'mourir' à l'extrémité du bus sur le bouchon. Utilisation de câble coaxial pour réaliser des réseaux Ethernet 10base2 et 10base5. Si un nœud du bus est déconnecté le réseau entier tombe.
Boucle (anneau) : réseau décentralisé type point à point. Ex : Token Ring dIBM. L'information transite par chacun d'eux et retourne à l'expéditeur
Maillé : tous les nœuds sont connectés entre eux
Arbre : hiérarchique. Les nœuds sont reliés aux nœuds supérieurs (ex réseau téléphonique)
Open System Interconnexion : assure interopérabilité des systèmes communicant par réseau.
L’interopérabilité des systèmes est garantie par la définition de relation verticale (interface) dans le découpage en couche des différents logiciels réseaux et de relation horizontale (protocole d’échange) entre deux couches de deux systèmes.
Les différents logiciels réseaux sont réparties en 7 couches dont les couches 1, 2, 3 et 4 qui réalise la transmission de l’information et les couches 5, 6 et 7 qui traite, gère l’application.

Figure 22 : Les 7 couches du modèle OSI
Niveau 1 : couche physique + couche physique ; transmission de séquence de bit sur un circuit de communication (média) entre deux systèmes. Les éléments de la couche physique sont : support physique, codeur, modulateur, multiplexeur, concentrateur.
Niveau 2 : couche liaison (utilise la couche physique) ; gestion de la liaison de donnée : données de l’émetteur en trame de données, transmission des trames en séquence, gestion des trames d’acquittement, reconnaissances des frontières des trames envoyées par la couche physiques ; détection et reprise sur erreur : régulation du trafic et gestions des erreurs ; procédures de transmissions (HDLC, LLC, DSC)
Niveau 3 : couche réseau (interconnexion de réseau hétérogène) ; fournit le moyen d’établir, de maintenir et de libérer des connexions de réseaux entre des systèmes ouverts : gestion de sous réseau, acheminement des paquets de la source vers la destination ; fonctionnalités d’adressage, de routage et de contrôle de flux ; Mode connecté ou non connecté ; Exemple IP
Niveau 4 : couche transport ; Indépendant des réseaux sous-jacents ; Accepte les données de la couche session les découpe et les ordonne ; fonctionnalités de bout en bout ; dépendance aux services réseaux de QoS. Ex : TCP, UDP
Niveau 5 : couche session ; met en place et contrôle la connexion (synchronisation) entre deux processus : gestion du dialogue, point de reprise, retour arrière
Niveau 6 : couche présentation : s’intéresse à la syntaxe et à la sémantique de l’information échangée entre deux applications : modèle de donnée échangé, compression et chiffrement.
Niveau 7 : couche application
L’IPV6 permet de traiter de façon adaptée les flux en temps réel, de sélectionner un fournisseur de service et l’adressage multipoint.
Adresse anycast : sélection du fournisseur d’accès en fonction de critère de bande passante de qualité de service, de prix, etc.
Indicateur de flux : pour repérer les paquets d’un même type de flux
Niveau de priorité :
Asynchronous Transfer Mode : technique de commutation et de multiplexage de cellules de longueurs fixes (53 bits). Il fonctionne avec un débit allant de 25 à 622 Mbps.
Fonctionnalités :
traite les flux en fonction de leur nature,
garantie de la bande passante.
Inconvénients : offres limités sur le marché français ; coûts prohibitifs (acquisition des Codecs MPEG2) ;
Avantages : adaptés pour la visioconférence
LAN: Local Area Network
Ces réseaux sont en général circonscrits à un bâtiment ou à un groupe de bâtiment pas trop éloignés les uns des autres (site universitaire, usine ou 'campus').
L'infrastructure est privée et est gérée localement par le personnel informatique.
De tels réseaux offrent en général une bande passante comprise entre 4Mbit/s et 100 Mbits/s.
WAN: Wide Area Network
Interconnexion de réseaux locaux et métropolitains à l'échelle de la planète, d'un pays, d'une région ou d'une ville.
L'infrastructure est en général publique (PTT, Télécom etc.). Les modems sont un des éléments de base des WANs. La bande passante va de quelques kbits/s à quelques Mbit/s. Une valeur typique pour une ligne louée est de 64kbits/s (en fonction des services offerts).
Un intranet est un ensemble de services Internet (par exemple un serveur web) internes à un réseau local, c'est-à-dire accessibles uniquement à partir des postes d'un réseau local, ou bien d'un ensemble de réseaux bien définis, et invisibles (ou inaccessibles) de l'extérieur. Il consiste à utiliser les standards client-serveur de l'internet (en utilisant les protocoles TCP/IP), comme par exemple l'utilisation de navigateurs internet (client basé sur le protocole HTTP) et des serveurs web (protocole HTTP), pour réaliser un système d'information interne à une organisation ou une entreprise.
Un extranet est une extension du système d'information de l'entreprise à des partenaires situés au-delà du réseau. Un extranet n'est donc ni un intranet, ni un site internet. Il s'agit d'un système supplémentaire offrant par exemple aux clients d'une entreprise, à ses partenaires ou à des filiales, un accès privilégié à certaines ressources informatiques de l'entreprise par l'intermédiaire d'une interface Web.
Internet est le réseau informatique mondial qui rend accessibles au public des services comme le courrier électronique et le World Wide Web. Techniquement, Internet se définit comme le réseau public mondial utilisant le protocole de communication IP (Internet Protocol).
En définitive, du point de vue de la confidentialité des communications, il importe de distinguer Internet des intranets, les réseaux privés au sein des entreprises, administrations, etc., et des extranets, interconnexions d'intranets pouvant emprunter Internet.
Quelles sont les différentes techniques d’accès à un média pour envoi et la réception d’information ? Qu'est-ce que CSMA/CD sur un réseau de type Ethernet ?
Consiste à nommer sur le réseau une machine responsable de gérer les accès en attribuant un droit de parole à chaque noeud de façon régulière ou en fonction de priorités ; cette tâche est en général accomplie par le serveur central. Cette méthode, appelée tour de table ou polling, tient difficilement compte des besoins réels de chaque noeud et ne permet pas une très grande souplesse; elle ne subsiste plus que dans certains gros systèmes à base de terminaux.
Il s'agit d'un système complètement déterministe.
Le droit de parole est attribué au possesseur d'un jeton (token) qui circule sur le réseau. Le noeud qui possède le jeton peut disposer du réseau; il le restitue lorsqu'il a fini de transmettre ses informations; un autre noeud peut ainsi en disposer.
Cette méthode, adoptée par IBM (TokenRing), convient particulièrement bien aux réseaux en anneau (ring).
En fonction de la longueur totale du câble, du nombre de stations et du temps de latence (temps mis par le paquet d'information pour traverser l'équipement) de chacune des stations, il est possible de calculer exactement la disponibilité du réseau pour chaque noeud. Il s'agit donc d'un système déterministe.
Ce type de méthode (et en particulier les réseaux TokenRing) offre un bon comportement à pleine charge, puisque de toute manière un droit de parole est attribué à intervalles fixes. Par contre, lors de faible trafic, ce mode de fonctionnement est pénalisant, puisque même si aucun autre noeud ne manifeste le besoin d'émettre sur le réseau, l'équipement désirant accéder au réseau doit attendre son tour.
Les mécanismes réglant la gestion d'un tel réseau sont particulièrement délicats à mettre en oeuvre.
CSMA/CD (Ethernet) : (Carrier Sense Multiple Access / Collision Detection)
Chaque noeud du réseau est à l'écoute du réseau (si un paquet lui est destiné, il le lit), et lorsqu'un équipement désire émettre un paquet, il ne le fait que si personne d'autre n'est train de transmettre ses propres paquets. Si le réseau est 'occupé', il attend un moment (calculé de façon aléatoire) et essaye à nouveau.
Compte tenu des caractéristiques physiques d'un réseau, un paquet (paquet 1) peut être émis par un noeud mais pas encore détectable par l'équipement désirant émettre; celui- ci transmet son paquet (paquet 2) à l'instant où le 'paquet 1' est détectable: il en résulte une collision.

Figure 22 : Accès au média par CSMA/CD sur bus Ethernet
En cas de collision, les noeuds impliqués émettent un signal pour signaler de façon certain l'événement à l'ensemble du réseau, puis essayent d'émettre à nouveau après un délai aléatoire.
Il en résulte qu'un tel réseau trop chargé fini par ne générer plus que des collisions, puisque tous les noeuds désirent émettre en même temps, alors que les 'plages' libres deviennent de moins en moins nombreuses.
On considère que les performances d'un tel réseau chutent après 30-40% de charge (3- 4 Mbits/s, à pondérer en fonction de différents paramètres, tels que la taille des paquets, le nombre de noeuds etc.).
La charge du réseau est donc un paramètre à surveiller de façon drastique si l'on ne veut pas se retrouver face à un réseau complètement surchargé et donc inutilisable.
Par contre, ses mécanismes sont relativement rustiques et sa mise en oeuvre assez simple.
Pour des raisons de physique électrique, la taille maximum des paquets envoyés sur le réseau est de 1518 bytes (12144 bits). La taille minimum est de 64 bytes (512 bits).
L'équipement récepteur a pour charge de remettre les paquets dans le bon ordre (dans le cas où, prenant des chemins différents, les paquets arrivent désordonnés) et de les ré-assembler. Cette tâche est accomplie par les couches supérieures.
RNIS : Réseau Numérique à Intégration de Service. Information numérique (son texte, vidéo) sur réseau étendu (Ex Numéris).
Sachant qu’il est impossible sur Internet de prédire le chemin emprunté par les différents paquets, la QoS permet de différencier les flux réseaux et de réserver une partie de la bande passante pour ceux nécessitant un service continu, sans coupures satisfaisant des exigences en matière de temps de réponse et de bande passante.
Trois niveaux de qualité de service :
Meilleur effort (en anglais best effort), ne fournissant aucune différenciation entre plusieurs flux réseaux et ne permettant aucune garantie. Ce niveau de service est ainsi parfois appelé lack of QoS.
Service différencié (en anglais differenciated service ou soft QoS), permettant de définir des niveaux de priorité aux différents flux réseau sans toutefois fournir une garantie stricte.
Service garanti (en anglais guaranteed service ou hard QoS), consistant à réserver des ressources réseaux pour certains types de flux. Le principal mécanisme utilisé pour obtenir un tel niveau de service est RSVP (Resource reSerVation Protocol, traduisez Protocole de réservation de ressources).
Débit
Gigue : fluctuation du signal numérique, dans le temps ou en phase
Latence, délai ou temps de réponse
Perte de paquet : non délivrance d'un paquet de données
Déséquencement : modification de l'ordre d'arrivée des paquets.
Mécanisme par lequel les données d'un équipement expéditeur sont acheminées jusqu'à leur destinataire, même si aucun des deux ne connaît le chemin complet que les données devront suivre.
Les différences entre les protocoles de routage :
ils peuvent échanger uniquement les changements dans les tables de routage comme le protocole OSPF.
ils peuvent aussi échanger toute la table de routage comme le protocole RIP ou IGRP
ou encore un hybride des deux comme EIGRP qui échangent la totalité des tables de routage dès qu'il y a modification de l'une d'elles.
OSPF (Open Shortest Path First) est un protocole de routage IP type protocole link-state (protocole à état de liens).
Ce protocole est plus performant que RIP et commence donc à le remplacer petit à petit. Contrairement à RIP qui envoie aux routeurs adjacents le nombre de sauts qui les séparent des réseaux IP, chaque routeur transmet à tous les routeurs du réseau par multicast (cf. ci-dessous), l'état de chacun de ses liens. De cette façon, chaque routeur est capable de se représenter le réseau sous la forme d'un graphe, et peut par conséquent choisir à tout moment la route la plus appropriée pour un message donné, et effectuer de l'équilibrage de charge. De plus, les mises à jour sont non périodiques et déclenchées sur des changements de topologie, ce qui entraîne un faible temps de convergence des tables de routage. Cependant, OSPF est complexe en implémentation et en configuration, et nécessite beaucoup de ressources pour stocker le graphe du réseau et effectuer les calculs sur celui-ci.
Routing Information Protocol (RIP, protocole d'information de routage) est un protocole de routage IP de type Vector Distance (Vecteur Distance) basé sur l'algorithme de routage décentralisé Bellman-Ford. Il permet à chaque routeur de communiquer aux autres routeurs la métrique, c’est-à-dire la distance qui les sépare du réseau IP (le nombre de sauts qui les sépare, ou « hops » en anglais compris entre 1 et 15). Ainsi, lorsqu'un routeur reçoit un de ces messages, il incrémente cette distance de 1 et communique le message aux routeurs directement accessibles.
Les routeurs peuvent donc conserver de cette façon la route optimale d'un message en stockant l'adresse du routeur suivant dans la table de routage de telle façon que le nombre de saut pour atteindre un réseau soit minimal. Les routes sont mises à jour toutes les 30 secondes.
Enhanced Interior Gateway Routing Protocol (EIGRP) est un protocole de routage développé par Cisco à partir de leur protocole original IGRP. EIGRP est un protocole de routage hybride IP, avec une optimisation permettant de minimiser l'instabilité de routage due aussi bien au changement de topologie qu'à l'utilisation de la bande passante et la puissance du processeur du routeur. Sa métrique est constitué de l’association de cinq différents métriques : délai, bande passante, fiabilité, charge, MTU (non utilisé dans le calcul de l'algorithme).
Wi-Fi est le nom de la certification pour les matériels respectant la norme 802.11. La norme IEEE 802.11 est un standard international décrivant les caractéristiques d'un réseau local sans fil (WLAN).
La norme définit les couches basses du modèle OSI pour une liaison sans fil utilisant des ondes électromagnétiques, c'est-à-dire :
la couche physique (notée parfois couche PHY), proposant trois types de codages de l'information.
la couche liaison de données, constitué de deux sous-couches : le contrôle de la liaison logique (Logical Link Control, ou LLC) et le contrôle d'accès au support (Media Access Control, ou MAC)
La couche physique définit la modulation des ondes radio-électriques et les caractéristiques de la signalisation pour la transmission de données, tandis que la couche liaison de données définit l'interface entre le bus de la machine et la couche physique, notamment une méthode d'accès proche de celle utilisée dans le standard ethernet et les règles de communication entre les différentes stations. La norme 802.11 propose en réalité trois couches physiques, définissant des modes de transmission alternatifs :
|
Couche Liaison de données |
802.2 |
|
|
802.11 |
|
Couche Physique ( |
DSSS FHSS Infrarouges
|
|
Standard |
Bande de fréquence |
Débit |
Portée |
|
WiFi a (802.11a) |
5 GHz |
54 Mbit/s |
10 m |
|
WiFi B (802.11b) |
2.4 GHz |
11 Mbit/s |
100 m |
|
WiFi G (802.11b) |
2.4 GHz |
54 Mbit/s |
100 m |
Les risques liés à la mauvaise protection d'un réseau sans fil sont multiples :
L'interception de données consistant à écouter les transmissions des différents utilisateurs du réseau sans fil
Le détournement de connexion dont le but est d'obtenir l'accès à un réseau local ou à internet
Le brouillage des transmissions consistant à émettre des signaux radio de telle manière à produire des interférences
Les dénis de service rendant le réseau inutilisable en envoyant des commandes factices (demande de déssassociation de station ; beaucoup de communication cryptée pour épuiser la batterie).
Infrastructure adapté : adapter la puissance d’émission par rapport à la zone à couvrir
Eviter les paramètres par défaut : mot de passe par défaut, nom du SSID, pas de broadcast du SSID.
Filtrage par adresse MAC
Le chiffrement :
WEP : algorithme symétrique RC4 avec des clés d'une longueur de 64 bits ou 128 bits ; vulnérable à une attaque par force brute (toutes les combinaisons de clé)
WPA (WiFi protected Access est une solution de
sécurisation de réseau WiFi proposé par la
WiFi Alliance, afin de combler les lacunes du WEP.
Le WPA
est une version « allégée » du
protocole 802.11i, reposant sur des protocoles d'authentification
et un algorithme de cryptage robuste : TKIP (Temporary
Key Integrity Protocol). Le protocole TKIP permet la génération
aléatoire de clés et offre la possibilité
de modifier la clé de chiffrement plusieurs fois par
secondes, pour plus de sécurité. Le
fonctionnement de WPA repose sur la mise en oeuvre d'un serveur
d'authentification (la plupart du temps un serveur RADIUS),
permettant d'identifier les utilisateurs sur le réseau et de
définir leurs droits d'accès. Néanmoins, il
est possible pour les petits réseaux de mettre en oeuvre une
version restreinte du WPA, appelée WPA-PSK, en
déployant une même clé de chiffrement dans
l'ensemble des équipements, ce qui évite la mise en
place d'un serveur RADIUS. Le WPA (dans sa première mouture)
ne supporte que les réseaux en mode infrastructure, ce qui
signifie qu'il ne permet pas de sécuriser des réseaux
sans fil d'égal à égal (mode ad hoc).
Le 802.11i a été ratifié le 24 juin 2004, afin de fournir une solution de sécurisation poussée des réseaux WiFi. Il s'appuie sur l'algorithme de chiffrement TKIP, comme le WPE, mais supporte également l'AES (Advanced Encryption Standard), beaucoup plus sûr.
La Wi-Fi Alliance a ainsi créé une nouvelle certification, baptisée WPA2, pour les matériels supportant le standard 802.11i (ordinateur portable, pda, carte réseau, etc.).
Contrairement au WPA, le WPA2 permet de sécuriser aussi bien les réseaux sans fil en mode infrastructure que les réseaux en mode ad hoc.
La norme IEEE 802.11i définit deux modes de fonctionnement :
WPA Personal : le mode « WPA personnel » permet de mettre en oeuvre une infrastructure sécurisée basée sur le WPA sans mettre en oeuvre de serveur d'authentification. Le WPA personnel repose sur l'utilisation d'une clé partagée, appelées PSK pour Pre-shared Key, renseignée dans le point d'accès ainsi que dans les postes clients. Contrairement au WEP, il n'est pas nécessaire de saisir une clé de longueur prédéfinie. En effet, le WPA permet de saisir une « passphrase » (phrase secrète), traduite en PSK par un algorithme de hachage.
WPA Enterprise : le mode entreprise impose l'utilisation d'une infrastructure d'authentification 802.1x basée sur l'utilisation d'un serveur d'authentification, généralement un serveur RADIUS (Remote Authentication Dial-in User Service), et d'un contrôleur réseau (le point d'accès)
A quel type de réseau correspond les réseaux sans fils WIFI ? Comment s'appelle l'identifiant de la borne d'accès ? Comment fonctionne la connexion à un réseau hot spot ?
Le standard 802.11 définit deux modes opératoires :
Le mode infrastructure dans lequel les clients sans fils sont connectés à un point d'accès. Il s'agit généralement du mode par défaut des cartes 802.11b.
Le mode ad hoc dans lequel les clients sont connectés les uns aux autres sans aucun point d'accès.
Le mode infrastructure
En mode infrastructure chaque ordinateur station (notée STA) se connecte à un point d'accès via une liaison sans fil. L'ensemble formé par le point d'accès et les stations situés dans sa zone de couverture est appelé ensemble de services de base (en anglais basic service set, noté BSS) et constitue une cellule. Chaque BSS est identifié par un BSSID, un identifiant de 6 octets (48 bits). Dans le mode infrastructure, le BSSID correspond à l'adresse MAC du point d'accès.

Il est possible de relier plusieurs points d'accès entre eux (ou plus exactement plusieurs BSS) par une liaison appelée système de distribution (notée DS pour Distribution System) afin de constituer un ensemble de services étendu (extended service set ou ESS). Le système de distribution (DS) peut être aussi bien un réseau filaire, qu'un câble entre deux points d'accès ou bien même un réseau sans fil !

Un ESS est repéré par un ESSID (Service Set Identifier), c'est-à-dire un identifiant de 32 caractères de long (au format ASCII) servant de nom pour le réseau. L'ESSID, souvent abrégé en SSID, représente le nom du réseau et représente en quelque sort un premier niveau de sécurité dans la mesure où la connaissance du SSID est nécessaire pour qu'une station se connecte au réseau étendu.
Lorsqu'un utilisateur nomade passe d'un BSS à un autre lors de son déplacement au sein de l'ESS, l'adaptateur réseau sans fil de sa machine est capable de changer de point d'accès selon la qualité de réception des signaux provenant des différents points d'accès. Les points d'accès communiquent entre eux grâce au système de distribution afin d'échanger des informations sur les stations et permettre le cas échéant de transmettre les données des stations mobiles. Cette caractéristique permettant aux stations de "passer de façon transparente" d'un point d'accès à un autre est appelé itinérance (en anglais roaming).
La communication avec le point d'accès
Lors de l'entrée d'une station dans une cellule, celle-ci diffuse sur chaque canal un requête de sondage (probe request) contenant l'ESSID pour lequel elle est configurée ainsi que les débits que son adaptateur sans fil supporte. Si aucun ESSID n'est configuré, la station écoute le réseau à la recherche d'un SSID.
En effet chaque point d'accès diffuse régulièrement (à raison d'un envoi toutes les 0.1 secondes environ) une trame balise (nommée beacon en anglais) donnant des informations sur son BSSID, ses caractéristiques et éventuellement son ESSID. L'ESSID est automatiquement diffusé par défaut, mais il est possible (et recommandé) de désactiver cette option.
A chaque requête de sondage reçue, le point d'accès vérifie l'ESSID et la demande de débit présents dans la trame balise. Si l'ESSID correspond à celui du point d'accès, ce dernier envoie une réponse contenant des informations sur sa charge et des données de synchronisation. La station recevant la réponse peut ainsi constater la qualité du signal émis par le point d'accès afin de juger de la distance à laquelle il se situe. En effet d'une manière générale, plus un point d'accès est proche, meilleur est le débit.
Une station se trouvant à la portée de plusieurs points d'accès (possédant bien évidemment le même SSID) pourra ainsi choisir le point d'accès offrant le meilleur compromis de débit et de charge.
Le mode ad hoc
En mode ad hoc les machines sans fils clientes se connectent les unes aux autres afin de constituer un réseau point à point (peer to peer en anglais), c'est-à-dire un réseau dans lequel chaque machine joue en même temps le rôle de client et le rôle de point d'accès.

L'ensemble formé par les différentes stations est appelé ensemble de services de base indépendants (en anglais independant basic service set, abrégé en IBSS).
Un IBSS est ainsi un réseau sans fil constitué au minimum de deux stations et n'utilisant pas de point d'accès. L'IBSS constitue donc un réseau éphémère permettant à des personnes situées dans une même salle d'échanger des données. Il est identifié par un SSID, comme l'est un ESS en mode infrastructure.
Dans un réseau ad hoc, la portée du BSS indépendant est déterminée par la portée de chaque station. Cela signifie que si deux des stations du réseaux sont hors de portée l'une de l'autre, elles ne pourront pas communiquer, même si elles "voient" d'autres stations. En effet, contrairement au mode infrastructure, le mode ad hoc ne propose pas de système de distribution capable de transmettre les trames d'une station à une autre. Ainsi un IBSS est par définition un réseau sans fil restreint.
High-Level Data Link Control : Protocole de couche niveau 2 ; protocole qui définit un mécanisme pour délimiter des paquets de différents types, en ajoutant un contrôle d'erreur.
Virtuel Local Network : réseau local regroupant un ensemble de machine de façon logique et non physique. Il permet de définir un réseau au dessus du réseau physique et offre par la même :
plus de souplesse pour l’administration et les modifications du réseau car toute l’architecture peut être modifier par simple paramétrage du commutateur ;
gain en sécurité car les informations sont encapsulés dans un niveau supplémentaire et éventuellement analysées ;
réduction du trafic sur le réseau
Quelles sont les différences entre un VLAN de niveau 1, 2 et 3 ? Qu'est-ce que la commutation de niveau 2, 3 4 et 7 ?
La différence se situe selon le critère de commutation et de niveau
VLAN de niveau 1 : VLAN par port ; définit un réseau virtuel en fonctions des ports de raccordement sur le commutateur.
VLAN de niveau 2 : VLAN MAC ; définit un réseau virtuel en fonction des adresses MAC des stations. Beaucoup plus souple que le VLAN par port car le réseau est indépendant de la localisation de la station.
VLAN de niveau 3 :
VLAN par sous réseau : associe des sous réseaux en fonctions de l’adresse IP sources des datagrammes. Grande souplesse car la configuration des commutateurs se modifient automatiquement en cas de déplacement d’une station. Par contre, légère chute des performances car analyse de la trame.
VLAN par protocole : définit un réseau en fonction du protocole (TCP/IP, IPX, AppleTalk, etc) utilisé.
IEEE 802.1D, IEEE 802.1Q et IEEE 802.1O
Les commutateurs pour le VLAN de niveau 1 et 2.
Les routeurs pour les VLAN de niveau 3
Réseau privé virtuel (noté RPV ou VPN, acronyme de Virtual Private Network)
Utilise Internet comme
support de transmission en utilisant un protocole d'"encapsulation"
chiffrée.
Ce réseau est dit virtuel car il
relie deux réseaux "physiques" (réseaux
locaux) par une liaison non fiable (Internet), et privé
car seuls les ordinateurs des réseaux locaux de part et
d'autre du VPN peuvent "voir" les données.
Le système de VPN permet donc d'obtenir une liaison sécurisée à moindre coût, si ce n'est la mise en oeuvre des équipements terminaux. En contrepartie il ne permet pas d'assurer une qualité de service comparable à une ligne louée dans la mesure où le réseau physique est public et donc non garanti.
Les principaux protocoles de tunneling sont les suivants :
PPTP (Point-to-Point Tunneling Protocol) est un protocole de niveau 2 : créer des trames sous le protocole PPP et de les encapsuler dans un datagramme IP
L2F (Layer Two Forwarding) est un protocole de niveau 2 développé par Cisco, Northern Telecom et Shiva. Il est désormais quasi-obsolète
L2TP (Layer Two Tunneling Protocol) est l'aboutissement des travaux de l'IETF (RFC 2661) pour faire converger les fonctionnalités de PPTP et L2F. Il s'agit ainsi d'un protocole de niveau 2 s'appuyant sur PPP.
IPSec est un protocole de niveau 3, issu des travaux de l'IETF, permettant de transporter des données chiffrées pour les réseaux IP.
Réseau virtuel ; Au-dessus de IP pour supporter le routage multicast IP entre machines communicantes. Les paquets Multicast sont encapsulés dans des paquets Unicast IP et sont transmis au moyen d’une liaison dite « tunnel » qui fait le lien entre Internet et les réseaux locaux. Chaque site relié à Mbone possède sa station tunnel.
Le routage Multicast est soit effectué selon le protocole DVMRP (Distance Vector Multicast Routing Protocol) ou PIM
Resource reSerVation Protocol : Protocole pour réserver de la bande passante pour une application ou un client. Il utilise les contraintes spécifiées en terme de qualité de service (QoS) et aux classes de service (CoS) pour une gestion quantitative de la bande passante.
User Datagramme Protocol : protocole de transport non orienté connexion pour l’IP (OSI niveau 4 ; couche transport du modèle TCP/IP) sans contrôle d’erreur, sans remise en ordre des paquets et sans procédure d’acquittement. Il permet de réaliser des échanges temps réel et de faire du multipoint.
Differentiated Services : système d’affection de priorités qui distingue 3 types de trafic et qui les classe dans des files d’attente différentes : Expedited Forwarding, Assured Forwarding et Default Forwarding.
La mise en oeuvre du principe consiste à marquer les paquets sur le champ Type of Service (ToS) soit à partir du poste de travail soit à partir de l’équipement d’entrée du réseau.
Integrated services : basé sur le protocole RSVP ; réserve un circuit virtuel du demandeur au demandé (émulation du fonctionnement de l’ATM).
Un Service Web est un programme informatique permettant la communication et l'échange de données entre applications et systèmes hétérogènes dans des environnements distribués. Il s'agit donc d'un ensemble de fonctionnalités exposées sur Internet ou sur un Intranet, par et pour des applications ou machines, sans intervention humaine, et en temps réel.
Il existe plusieurs technologies derrière le terme Services Web :
Les Services Web de type REST exposent entièrement ces fonctionnalités comme un ensemble de ressources (URI) identifiables et accessibles par la syntaxe et la sémantique du protocole HTTP. Les Services Web de type REST sont donc basés sur l'architecture du Web et ses standards de base : HTTP et URI.
Les Services Web WS-* exposent ces mêmes fonctionnalités sous la forme de services exécutables à distance. Leurs spécifications reposent sur les standards SOAP et WSDL pour transformer les problématiques d'intégration héritées du monde Middleware en objectif d'interopérabilité. Les standards WS-* sont souvent décriés comme l'étaient leurs ancêtres CORBA, RMI ou DCOM : des technologies complexes héritées du vieux principe RPC, fortement couplées et difficilement inter opérables dans des environnements hétérogènes. A contrario, le Web est par nature une plateforme inter opérable.
Système (souvent c'est un logiciel particulier) qui fusionne (fonction de réplication ou de synchronisation) les différents annuaires d'une organisation (téléphone, mail...).
Deux types de méta-annuaires (proxy LDAP) :
les méta-annuaires avec réplication créant une base de donnée issue de l'agrégation des données provenant des différents annuaires
les méta-annuaires "virtuels" créant des références centrales vers les données contenues dans les différents annuaires, mais ne dupliquant pas l'information
Lightweight Directory Access Protocol (LDAP) est à l'origine un protocole permettant l'interrogation et la modification des services d'annuaire. Ce protocole repose sur TCP/IP.
LDAP (Lightweight Directory Access Protocol, traduisez Protocole d'accès aux annuaires léger et prononcez "èl-dap") est un protocole standard permettant de gérer des annuaires, c'est-à-dire d'accéder à des bases d'informations sur les utilisateurs d'un réseau par l'intermédiaire de protocoles TCP/IP. Les bases d'informations sont généralement relatives à des utilisateurs, mais elles sont parfois utilisées à d'autres fins comme pour gérer du matériel dans une entreprise.
Le protocole LDAP, développé en 1993 par l'université du Michigan, avait pour but de supplanter le protocole DAP (servant à accéder au service d'annuaire X.500 de l'OSI), en l'intégrant à la suite TCP/IP.
Le service d'annuaire X.500 était un standard conçu en 1988 par les opérateurs télécoms prévu pour interconnecter tout type d'annuaire dans un but de normalisation. Celui-ci définit :
des règles de nommages pour les éléments qu'il contient
des protocoles d'accès à l'annuaire (dont DAP)
des moyens d'authentification de l'utilisateur
Toutefois, la norme X500 était basée sur les protocoles ISO et impliquait donc une mise en place très lourde. Ainsi, en 1993 l'université du Michigan a adapté le protocole DAP de la norme X.500 au protocole TCP/IP et a mise au point LDAP.
A partir de 1995, LDAP est devenu un annuaire natif (standalone LDAP), afin de ne plus servir uniquement à accéder à des annuaires de type X500, c'est-à-dire en gérant sa propre base de données. LDAP est ainsi une version allégée du protocole DAP, d'où son nom de Lightweight Directory Access Protocol prévu pour fonctionner avec les protocoles TCP/IP.
Le protocole LDAP définit la méthode d'accès aux données sur le serveur au niveau du client, et non la manière de laquelle les informations sont stockées.
Le protocole LDAP est uniquement prévu pour gérer l'interfaçage avec les annuaires. Plus exactement il s'agit d'une norme définissant la façon suivant laquelle les informations sont échangées entre le client et le serveur LDAP ainsi que la manière dont les données sont représentées. Ainsi, ce protocole se conforme à quatre modèles de base :
un modèle d'information : définissant le type d'information stockée dans l'annuaire
un modèle de nommage (parfois appelé modèle de désignation) : définissant la façon de laquelle les informations sont organisées dans l'annuaire et leur désignation
un modèle fonctionnel (parfois appelé modèle de services) : définissant la manière d'accéder aux informations et éventuellement de les modifier, c'est-à-dire les services offerts par l'annuaire.
un modèle de sécurité : définissant les mécanismes d'authentification et de droits d'accès des utilisateurs à l'annuaire.
De plus, LDAP définit la communication entre
Le client et le serveur, c'est-à-dire les commandes de connexion et de déconnexion au serveur, de recherche ou de modification des entrées
Les serveurs eux-mêmes, pour définir d'une part le service de réplication (replication service), c'est-à-dire un échange de contenu entre serveurs et synchronisation, d'autre part pour créer des liens entre les annuaires (on parle de referral service).
Le format des données dans le protocole LDAP n'est pas le format ASCII comme c'est le cas pour la plupart des protocoles mais une version allégée du Basic Encoding Rules (BER) appelée Lightweight Basic Encoding Rules (LBER).
D'autre part, LDAP fournit un format d'échange (LDIF, Lightweight Data Interchange Format) permettant d'importer et d'exporter les données d'un annuaire avec un simple fichier texte.
Enfin il existe un certain nombre d'API (Application Programming Interface, c'est-à-dire des interfaces de programmation) permettant de développer des applications clientes permettant de se connecter à des serveurs LDAP avec différents langages Ainsi LDAP fournit à l'utilisateur des méthodes lui permettant de :
se connecter
se déconnecter
rechercher des informations
comparer des informations
insérer des entrées
modifier des entrées
supprimer des entrées
D'autre part, le protocole LDAP (dans sa version 3) propose des mécanismes de chiffrement (SSL, ...) et d'authentification (SASL) permettant de sécuriser l'accès aux informations stockées dans la base.
De plus, contrairement à la plupart des protocoles, LDAP permet d'effectuer plusieurs requêtes sur le serveur d'annuaire à l'aide d'une seule connexion. En effet, le protocole HTTP ne permet d'effectuer qu'une et une seule requête à chaque connexion au serveur.

Un annuaire est un type de base de données spécifique, c'est-à-dire qu'il s'agit d'une sorte de base de données ayant des caractéristiques particulières :
un annuaire est prévu pour être plus sollicité en lecture qu'en écriture. Cela signifie qu'un annuaire est conçu pour être plus souvent consulté que mis à jour.
les données sont stockées de manière hiérarchique dans l'annuaire, tandis que les bases de données dites "relationnelles" stockent les enregistrements de façon tabulaire.
les annuaires doivent être compacts et reposer sur un protocole réseau léger
Un annuaire doit comporter des mécanismes permettant de rechercher facilement une information et d'organiser les résultats
les annuaires doivent pouvoir être répartis. Cela signifie qu'un serveur d'annuaire doit comporter des mécanismes permettant de coopérer, c'est-à-dire d'étendre la recherche sur des serveurs tiers si jamais aucun enregistrement n'est trouvé
L’authentification : un annuaire doit être capable de gérer l'authentification des utilisateurs ainsi que les droits de ceux-ci pour la consultation ou la modification de données
Ainsi, un annuaire est généralement une application se basant sur une base de données afin d'y stocker des enregistrements, mais surtout un ensemble de services permettant de retrouver facilement les enregistrements à l'aide de requêtes simples. Une base de données par contre n'est pas forcément un annuaire...
Network Time Protocol (NTP, protocole horaire en réseau), est un protocole permettant de synchroniser les horloges des systèmes informatiques à travers un réseau de paquets, dont la latence est variable. Utilise le temps universel coordonné (UTC).
NTP définit une architecture, différentes méthodes et algorithmes visant à limiter au maximum la dérive par rapport à cette heure de référence, dû au temps de transmission.
Le réseau NTP est composé :
de récepteurs récupérant l'heure de référence par radios, câbles, satellites ou directement depuis une horloge atomique.
de serveurs de temps récupérant l'heure de référence auprès des récepteurs ou bien auprès d'autres serveurs de temps
de clients récupérant l'heure de référence auprès des serveurs de temps

Le temps est défini comme un entier de 64 bits :
les 32 bits de poids forts correspondent au nombre de secondes écoulées depuis le 1er janvier 1900 à minuit
les 32 bits restant représentent la fraction d'une seconde
L'échelle de temps est donc de 232 secondes (soit un peu plus de 136 ans), avec une résolution théorique de 2-32 seconde (ce qui correspond à un peu moins de 0,233 nanosecondes).
NTP utilise l'algorithme de Marzullo et prend en charge l'ajout de secondes additionnelles. La version 4 du protocole permet de maintenir le temps d'une machine avec une précision de 10 ms à travers Internet et peut permettre une précision de 200 µs sur des réseaux locaux.
Méthode de sécurisation des accès aux ressources des machines à l’aide d’un identifiant unique, lorsque l’on navigue sur Internet ou intranet. Une plate-forme SSO attribue à chaque nouvel arrivant lorsqu’il s’identifie, ses droits et les transmet à chaque application qu’il va utiliser.
Objectifs :
simplifier pour l'utilisateur la gestion de ses mots de passe
simplifier la gestion des données personnelles détenues par les différents services en ligne, en les coordonnant par des mécanismes de type méta annuaire
simplifier la définition et la mise en œuvre de politiques de sécurité
Architectures :
Approche centralisée : Le principe de base est ici de disposer d'une base de données globale et centralisée de tous les utilisateurs ou d'un annuaire. Cela permet également de centraliser la gestion de la politique de sécurité. Cette approche est principalement destinée à des services dépendant tous d'une même entité, par exemple à l'intérieur d'une société.
Approche fédérative : chaque service gère une partie des données d'un utilisateur (l'utilisateur peut donc disposer de plusieurs comptes), mais partage les informations dont il dispose sur l'utilisateur avec les services partenaires. Cette approche a été développée pour répondre à un besoin de gestion décentralisée des utilisateurs, où chaque service partenaire désire conserver la maîtrise de sa propre politique de sécurité
Approche coopérative : principe que chaque utilisateur dépend d'une des entités partenaires. Ainsi, lorsqu'il cherche à accéder à un service du réseau, l'utilisateur est authentifié par le partenaire dont il dépend. Comme dans l'approche fédérative, cependant, chaque service du réseau gère indépendamment sa propre politique de sécurité. Cette approche répond notamment aux besoins de structures institutionnelles dans lesquelles les utilisateurs sont dépendants d'une entité, comme par exemple les universités, les laboratoires de recherche, les administrations.
Simple Network Management Protocol (SNMP), protocole simple de gestion de réseau en Français, est un protocole de communication qui permet aux administrateurs réseau de gérer les équipements du réseau, superviser et de diagnostiquer des problèmes réseaux, matériels à distance.
Le système de gestion de réseau est basé sur trois éléments principaux: un superviseur, des nœuds (ou nodes) et des agents.
Le superviseur est la console qui permet à l'administrateur réseau d'exécuter des requêtes de management. Les agents sont des entités qui se trouvent au niveau de chaque interface, connectant l'équipement managé (nœud) au réseau et permettant de récupérer des informations sur différents objets.
SNMP permet le dialogue entre le superviseur et les agents afin de recueillir les objets souhaités dans la MIB.
L'architecture de gestion du réseau proposée par le protocole SNMP est donc fondée sur trois principaux éléments :
Les équipements managés (managed devices) sont des éléments du réseau (ponts, switches, hubs, routeurs ou serveurs), contenant des « objets de gestion » (managed objects) pouvant être des informations sur le matériel, des éléments de configuration ou des informations statistiques ;
Les agents, c'est-à-dire une application de gestion de réseau résidant dans un périphérique et chargé de transmettre les données locales de gestion du périphérique au format SNMP ;
Les systèmes de management de réseau (network management system notés NMS), c'est-à-dire une console à travers laquelle les administrateurs peuvent réaliser des tâches d'administration.
SNMP est utilisé:
pour administrer les équipements
pour surveiller le comportement des équipements.
Une requête SNMP est un datagramme UDP habituellement à destination du port 161. Le protocole SNMP définit aussi un concept de trap : l'agent envoie un paquet UDP à un serveur Les traps SNMP sont envoyés en UDP/162.
MIB (« Management Information Base ») : une sorte de base de données arborescente contenant les objets manageables par SNMP.
Les objets manageables sont directement liés au comportement en cours de l’équipement surveillés. Ils peuvent être :
des informations matérielles,
des paramètres de configuration,
des statistiques de performance.
Exemples d’équipement possédant des objets manageables : Switchs, hubs, routeurs et serveurs.
Les contraintes sont :
Le délai de transmission
La gigue
Le taux de perte des paquets : dépend de l’information véhiculée ; besoin de Qualite Of Service (QoS), de réservation de ressources (RSVP).
Mode non connecté et non fiable (UDP) : comme les contraintes de délai empêche utilisation de protocole fiable (ex TCP)
Utilisation de RTP avec UDP ; privilégie la continuité au détriment de la fiabilité
La voix sur réseau IP, ou « VoIP » pour Voice over IP, est une technique qui permet de communiquer par la voix via l'Internet ou tout autre réseau acceptant le protocole TCP/IP. Cette technologie est notamment utilisée pour supporter le service de téléphonie IP (« ToIP » pour Telephony over Internet Protocol).

Figure 22 : les protocoles de transport de la VoIP
Les principaux protocoles utilisés pour l'établissement des connexions en voix sur IP sont : H323, SIP, IAX
Les principaux protocoles utilisés pour le transport de la voix elle-même sont : RTP, RTCP.
La voix ou le son sur IP peut se faire en mode :
Unicast : mode « point à point » ; Le protocole H.323 ne fonctionne qu'en mode Unicast
Broadcast : mode « une émission et plusieurs réceptions » (comme un émetteur TV, par ex.)
Multicast : mode « une émission pour plusieurs réceptions » (mais le signal n'est routé que s'il y a des récepteurs).
Les contraintes :
Le délais de latence : doit être inférieur à 200 ms (ex cuivre et fibre optique 60 ms) ; difficile en liaison satellite ente 400 et 800 ms
La gigue : les fluctuations du signal en amplitude et fréquence nécessitent un mécanisme de remise en ordre des paquets afin de restituer le message vocal, processus qui se traduira par des blancs et des attentes.
SIP (Session Initiation Protocol) : standard Internet pour établir, modifier et terminer des sessions multimédia. Permet l'authentification, la localisation des multiples participants, et la négociation des types de média.
Le multipoint et la rationalisation de la bande passante : utilisation de l’adressage multipoint ou du Multicast backbone pour l’émission d’un seul paquet et d’une liste de diffusion utilisée par les routeurs Internet pour ne réaliser la diffusion que sur les nœuds clés.
La re-synchronisation : compense l’utilisation de réseau non déterministe pour transporter des données synchrones.
La gestion de la congestion : pour éviter la saturation des nœuds et des liaisons utilisation de la compression et/ou diminution du taux de rafraîchissement ; conséquences : appauvrissement de l’information.
La priorité des flux multimédia : gestion des priorités dans les protocoles (automatiquement) soit par réservation de ressource (à la demande).
Un Hub est un
concentrateur et un Switch un commutateur...
Quand le Hub reçoit
une information il l'envoit "partout", alors que le Switch
qui reçoit une information la redirige uniquement vers le bon
destinataire...
Donc un Hub a les même fonctions qu'un
Switch mais le Switch est beaucoup plus performant! Actuellement, vue
de la différence de prix entre les deux, il vaut mieux acheter
un Switch!
Les Repeaters (répéteur) sont à comparer à des amplificateurs qui régénèrent le signal et qui permettent ainsi d'étendre la distance maximum de transmission. Le réseau reste unique, les collisions sont propagées. Ce type d'équipement ne nécessite aucune configuration logicielle. Niveau 1 OSI.
Les Hubs (concentrateurs) permettent la connexion de plusieurs noeuds sur un même point d'accès sur le réseau, en se partageant la bande passante totale.
La structure physique qui s'en dégage est une étoile, mais la topologie logique reste un bus (pour Ethernet).
Niveau 1 OSI
Les Bridges (pont) font partie des équipements d'interconnexion et possèdent au minimum 2 ports. Ce type d'équipement, logiciel et matériel, assure une segmentation physique et logique du réseau. Seul les paquets destinés à un équipement situé de l'autre côté du Bridge le traverse. Le trafic est filtré, les collisions ne sont pas propagées. Les Bridges effectuent leur tri (le paquet doit-il passer ou non) sur les adresses physiques des paquets.
La configuration logicielle de ce type d'équipement est en général automatique
Niveau 2 OSI.
Un Router (routeur, appelé aussi abusivement Gateway) est également un équipement d'interconnexion muni de 2 ports au minimum et ayant une adresse physique et logique pour chacun d'eux qui réalise l’interconnexion de réseau hétérogène.
Il réalise l'aiguillage (routage) et le filtrage des paquets à travers le réseau : les paquets passent d'un routeur à l'autre en fonction d'un chemin (route) calculé d'entente entre les routeurs du réseau (et ceci à l'échelle mondiale d'Internet), d'après une série de protocoles de routage (OSPF ou RIP).
Niveau 3 OSI.
Equipement qui relie deux réseaux de nature différent entre eux.
Niveau 7 OSI
Le premier câble Ethernet à avoir été standardisé. Il s'agit d'un câble coaxial blindé de 50 Ohm, terminé, d'un diamètre de près de 2cm, utilisable sur une distance de 500m sans ré- amplification du signal électrique. La bande passante est de 10Mbits/s.
Ses dimensions le rendent malaisé à poser et sa 'connectique' est délicate: en effet, il faut perforer l'enveloppe du câble pour y introduire une aiguille permettant la connexion sur un tranceiver (émetteur) externe.
Physiquement, il s'agit d'un bus, puisque tous les noeuds se connectent les uns à côté des autres (la distance entre deux connections sur le câble doit être, pour des raisons de physique électrique, d'un multiple de 1,5m).
La connexion d'une
machine sur le réseau s'effectue à travers son port AUI
(Access Unit Interface) de 15 pôles, un câble AUI d'une
longueur maximum de 5m et d'un 'Tranceiver' permettant la jonction
physique sur le câble coaxial.
Le câble coaxial fin de 50 Ohm, appelé aussi 'CheaperNet', terminé et facile à poser est apparu après le Thick Ethernet et présente les caractéristiques suivantes:
- longueur maximum sans ré-amplification: 185m.
- connecteurs de type BNC à baïonnettes, branchement à l'aide de connecteurs en 'T', le nombre de connexions maximums par segment de 185m est de 30.
- bande passante de 10Mbits/s.
Il s'agit également de câble de type 'bus', puisque tous les noeuds se connectent les uns à coté des autres. Sa connectique délicate en fait un câble facilement sujet à des perturbations intermittentes difficilement éliminables.
10Base-T (Câblage universel structuré (UTP/STP)) :
Ce câble reprend le principe du câble téléphonique puisqu'il s'agit d'un câblage physique en étoile (chaque prise est reliée à un noeud central, appelé répartiteur ou 'Hub'; il est donc structuré) à base de conducteurs en cuivre torsadés entre eux afin de pallier l'absence d'un épais isolant (lutte contre la diaphonie).
Chaque câble est constitué de 8 conducteurs de cuivre, isolés par un enrobage plastique et torsadés par paire.
Un blindage (Schielded Twisted Pair) extérieur peut être ajouté afin de lutter contre les phénomènes électromagnétiques: c'est la solution qui a été adoptée sur le réseau des Hospices, vu l'environnement 'agressif' du CHUV.
Ce type de câblage prend le nom d'universel, car il permet le passage de différents types d'informations: réseau informatique Ethernet ou TokenRing, téléphonie, domotique, vidéo etc.
La distance maximum atteignable, en Ethernet et sans ré-amplification, sur de tels câbles est de 100m (y compris les câbles de renvois et les câbles de bureau !).
La bande passante potentielle, pour des câbles certifiés de catégorie 5, est de 100Mbits/s.
|
Normes |
Débits |
Topologie |
Porté |
Particularités |
|
10Base5 |
10 Mb/s |
Bus |
500 m |
Connexion par piquage avec ajout de transceivers |
|
10Base2 |
10 Mb/s |
Bus |
180 m |
Connexion avec un T |
|
10Base-T |
100 Mb/s en catégorie 5 |
Etoile |
100m |
Utilisation de Hub |
C’est un codage électrique utilisé pour l’information électrique sur un câble 10BaseT.
Ses caractéristiques répondent aux besoins suivants :
bonne immunité au bruit électromagnétique (parasites).
pas de composante continue afin de diminuer les pertes électriques (effet Joule).
possibilité d'inverser la polarité.
Le code Manchester Bi-Phasé correspond à une modulation en bande de base, c'est-à-dire que le signal binaire est transformé en un signal de type analogique sans être translaté en fréquence (par opposition à un signal radio).

La norme 10BaseT ajoute au signal Manchester contenant l'information, des pulses électriques permettant de s'assurer que la connexion point à point entre l'équipement émetteur (station de travail par exemple) et l'équipement récepteur (un Hub) est valide (link).
Le DoS
Une « attaque par déni de service » (en anglais « Denial of Service », abrégé en DoS) est un type d'attaque visant à rendre indisponible pendant un temps indéterminé les services ou ressources d'une organisation. On distingue habituellement deux types de dénis de service :
Les dénis de service par saturation, consistant à submerger une machine de requêtes, afin qu'elle ne soit plus capable de répondre aux requêtes réelles ; exemple une attaque DoS en SYN (demande de connexion TCP en trois temps (SYN, SYN/ACK, ACK) sans ACK le serveur accumule les ouvertures de connexion en cours et fini par saturer.
Les dénis de service par exploitation de vulnérabilités, consistant à exploiter une faille du système distant afin de le rendre inutilisable.
Le principe des attaques par déni de service consiste à envoyer des paquets IP ou des données de taille ou de constitution inhabituelle, afin de provoquer une saturation ou un état instable des machines victimes et de les empêcher ainsi d'assurer les services réseau qu'elles proposent.
Pour se protéger :
Mise à jour de sécurité régulière
Ralentissement des requêtes identiques ou provenance d’une seule machine
L’attaque par réflexion
La technique dite « attaque par réflexion » (en anglais « smurf ») est basée sur l'utilisation de serveurs de diffusion (broadcast) pour paralyser un réseau. Un serveur broadcast est un serveur capable de dupliquer un message et de l'envoyer à toutes les machines présentes sur le même réseau.
Le Flood
![]() Le
flood consiste à envoyer très rapidement de gros
paquets d'information à une personne (à condition
d'avoir un PING (temps que met l'information pour faire un aller
retour entre 2 machines) très court). La personne visée
ne pourra plus répondre aux requêtes et le modem va donc
déconnecter. C'est cette méthode qui a été
employé à grande échelle dans l'attaque des
grands sites commerciaux (Yahoo, Etrade, Ebay, Amazon...) en février
2000.
Le
flood consiste à envoyer très rapidement de gros
paquets d'information à une personne (à condition
d'avoir un PING (temps que met l'information pour faire un aller
retour entre 2 machines) très court). La personne visée
ne pourra plus répondre aux requêtes et le modem va donc
déconnecter. C'est cette méthode qui a été
employé à grande échelle dans l'attaque des
grands sites commerciaux (Yahoo, Etrade, Ebay, Amazon...) en février
2000.![]() Pour
l'éviter une solution consiste à ne pas divulguer son
adresse IP (ce qui est possible pour un particulier, mais pas pour
une entreprise possédant un nom de domaine).
Pour
l'éviter une solution consiste à ne pas divulguer son
adresse IP (ce qui est possible pour un particulier, mais pas pour
une entreprise possédant un nom de domaine).
![]()
Les sniffers
Un « analyseur réseau » (appelé également analyseur de trames ou en anglais sniffer, traduisez « renifleur ») est un dispositif permettant d'« écouter » le trafic d'un réseau, c'est-à-dire de capturer les informations qui y circulent.
En effet, dans un réseau non commuté, les données sont envoyées à toutes les machines du réseau. Toutefois, dans une utilisation normale les machines ignorent les paquets qui ne leur sont pas destinés. Ainsi, en utilisant l'interface réseau dans un mode spécifique (appelé généralement mode promiscuous) il est possible d'écouter tout le trafic passant par un adaptateur réseau (une carte réseau ethernet, une carte réseau sans fil, etc.).
Pour se protéger :
On crypte les communication
En WIFI on réduit la puissance
On scanne le réseau à la recherche de matériel en mode promiscuous
On utilise des Switchs plutôt que des Hubs
Exemple
de sniffer : ethereal, windump, tcpdump
Les scanners : balayages de port (scanning)
![]() Un
scanner est un programme qui permet de savoir quels ports sont
ouverts sur une machine donnée. Les scanners servent pour les
hackers à savoir comment ils vont procéder pour
attaquer une machine. Leur utilisation n'est heureusement pas
seulement malsaine, car les scanners peuvent aussi vous permettre de
déterminer quels ports sont ouverts sur votre machine pour
prévenir une attaque.
Un
scanner est un programme qui permet de savoir quels ports sont
ouverts sur une machine donnée. Les scanners servent pour les
hackers à savoir comment ils vont procéder pour
attaquer une machine. Leur utilisation n'est heureusement pas
seulement malsaine, car les scanners peuvent aussi vous permettre de
déterminer quels ports sont ouverts sur votre machine pour
prévenir une attaque.
Les scanners fonctionnent de deux
manières :
L'acquisition active d'informations consistant à envoyer un grand nombre de paquets possédant des en-têtes caractéristiques et la plupart du temps non conformes aux recommandations et à analyser les réponses afin de déterminer la version de l'application utilisée. En effet, chaque application implémente les protocoles d'une façon légèrement différente, ce qui permet de les distinguer.
L'acquisition passive d'informations (parfois balayage passif ou scan non intrusif) est beaucoup moins intrusive et risque donc moins d'être détecté par un système de détection d'intrusions. Son principe de fonctionnement est proche, si ce n'est qu'il consiste à analyser les champs des datagrammes IP circulant sur un réseau, à l'aide d'un sniffer. La caractérisation de version passive analyse l'évolution des valeurs des champs sur des séries de fragments, ce qui implique un temps d'analyse beaucoup plus long. Ce type d'analyse est ainsi très difficile voire impossible à détecter.
Exemple de scanner : nmap
Le Nuke
![]() Les
nukes sont des plantages de Windows dus à des utilisateurs peu
intelligents (qui connaissent votre adresse IP) qui s'amusent à
utiliser un bug de Windows 95 (qui a été réparé
avec Windows 98) qui fait que si quelqu'un envoie à
répétition des paquets d'informations sur le port 139,
Windows affiche un magnifique écran bleu du plus bel effet,
qui oblige à redémarrer.
Les
nukes sont des plantages de Windows dus à des utilisateurs peu
intelligents (qui connaissent votre adresse IP) qui s'amusent à
utiliser un bug de Windows 95 (qui a été réparé
avec Windows 98) qui fait que si quelqu'un envoie à
répétition des paquets d'informations sur le port 139,
Windows affiche un magnifique écran bleu du plus bel effet,
qui oblige à redémarrer.
Le Mail Bombing
![]() Le
mail bombing consiste à envoyer plusieurs milliers de messages
identiques à une boîte aux lettres pour la faire
saturer. En effet les mails ne sont pas directs, ainsi lorsque vous
relèverez le courrier, celui-ci mettra beaucoup trop de temps
et votre boîte aux lettres sera alors inutilisable...
Le
mail bombing consiste à envoyer plusieurs milliers de messages
identiques à une boîte aux lettres pour la faire
saturer. En effet les mails ne sont pas directs, ainsi lorsque vous
relèverez le courrier, celui-ci mettra beaucoup trop de temps
et votre boîte aux lettres sera alors inutilisable...![]() Il
existe toutefois des solutions, avoir plusieurs boîtes aux
lettres permet de limiter les dégâts, une importante que
vous ne divulguez qu'aux personnes dignes de confiance, et une
à laquelle vous tenez moins. Des plus des logiciels
anti-spam existent, ils interdiront la réception de plusieurs
messages identiques à un intervalle de temps trop
court.
Il
existe toutefois des solutions, avoir plusieurs boîtes aux
lettres permet de limiter les dégâts, une importante que
vous ne divulguez qu'aux personnes dignes de confiance, et une
à laquelle vous tenez moins. Des plus des logiciels
anti-spam existent, ils interdiront la réception de plusieurs
messages identiques à un intervalle de temps trop
court.
Le spoofing IP
Le spoofing IP consiste
en une usurpation, par un utilisateur du réseau, d'une adresse
IP, afin de se faire passer pour la machine à laquelle cette
adresse correspond normalement. Cette technique repose sur les liens
d'authentification et d'approbation qui existent au sein d'un réseau.
Lorsque des machines sur un même réseau connaissent
l'adresse d'autres machines et qu'il existe des relations de
confiance entre elles, elles peuvent exécuter des
commandes
à distance.
L’ARP poisoning
Une des attaques man in the middle les plus célèbres consiste à exploiter une faiblesse du protocole ARP (Address Resolution Protocol) dont l'objectif est de permettre de retrouver l'adresse IP d'une machine connaissant l'adresse physique (adresse MAC) de sa carte réseau.
L'objectif de l'attaque consiste à s'interposer entre deux machines du réseau et de transmettre à chacune un paquet ARP falsifié indiquant que l'adresse ARP (adresse MAC) de l'autre machine a changé, l'adresse ARP fournie étant celle de l'attaquant.
Les deux machines cibles vont ainsi mettre à jour leur table dynamique appelée Cache ARP. On parle ainsi de « ARP cache poisoning » (parfois « ARP spoofing » ou « ARP redirect ») pour désigner ce type d'attaque.
De cette manière, à chaque fois qu'une des deux machines souhaitera communiquer avec la machine distante, les paquets seront envoyés à l'attaquant, qui les transmettra de manière transparente à la machine destinatrice.
Le terme « spam » désigne l'envoi massif de courrier électronique (souvent de type publicitaire) à des destinataires ne l'ayant pas sollicité et dont les adresses ont généralement été récupérées sur Internet.
Les spammeurs accumulent les adresses email principalement dans les forums en utilisant des programmes (robots).
Comment le combattre :
ne pas répondre (adresse de retour fausse ; moyen pour le spameur de détecter un adresse valide)
Les dispositifs antispam côté client, situé au niveau du client de messagerie. Il s'agit généralement de systèmes possédant des filtres permettant d'identifier, sur la base de règles prédéfinies ou d'un apprentissage (filtres bayésiens).
Les dispositifs antispam côté serveur, permettant un filtrage du courrier avant remise aux destinataires. Ce type de dispositif est de loin le meilleur car il permet de stopper le courrier non sollicité en amont et éviter l'engorgement des réseaux et des boîtes aux lettres.
Le résultat est la liste des ports (services) TCP ouverts sur le serveur. Il permet aussi d’obtenir des informations sur les applications, leurs numéros de version et le système d’exploitation du serveur.
Voir action d’un scanner.
Mettre en place un pare feu afin de gérer le flux IP en direction et en provenance de votre serveur. Exemple de pare feux CheckPoint, NetScreen, PIX, Zone Alarme ou IPtable.
Filtrer les messages ICMP auprès du réseau externe, par l'intermédiaire du pare feux. Cela forcera le pirate à employer de véritables balayages de port de TCP pour tracer votre réseau correctement, ce qui a pour avantage d'être logué par les IDS. Il faut aussi avoir conscience des impacts que cela peut engendrer. La première chose étant que l'on ne respecte plus les différentes RFC.
Filtrer les messages ICMP de type 3 (destination port unreachable) auprès des routeurs et pare-feux pour empêcher le balayage UDP et le firewalking d'être efficace.
Configurer correctement votre pare feux de sorte qu'il puisse identifier les balayages. Vous pouvez configurer les pare feux commerciaux (de type CheckPoint, NetScreen, PIX, ou IPtable) pour empêcher les balayages rapides de ports et les inondations SYN (SYN flood). Il y a beaucoup d'outils tels que portsentry qui peut identifier les scans et peut ignorer les paquets provenant d'un IP donnée pendant une période donnée.
L’objectif principal d’un scan est d’obtenir la liste des ports (services) ouvert sur le serveur. Il permet aussi de déterminer, en fonction de la séquence de datagramme IP envoyé la version de l’applicatif derrière un port ouvert.
La meilleure méthode pour masquer une intrusion est d’usurper une identité par IP spoofing par exemple.
Quels sont les protocoles de transfert sécurisé et comment fonctionnent-ils (https, sftp, ssh, ssl...) ? Décrire les mécanismes de HTTPS ?
Hypertext Transfer Protocol Secure : encapsulation de HTTP au travers du protocole SSL

HTTPS se voit attribué le port par défaut fixé à 443 de type TCP, il est utilisé de nos jours sur le très grand réseau mondial qu’est Internet mais aussi sur les réseaux Intranet nécessitant une confidentialité des données.

Etant basé sur un protocole de couche inférieure qu’est SSL, d’autres standards peuvent utilisé le même modèle. Nous avons ainsi entre autre:
|
HTTP HTTPS |
|
FTP FTPS |
|
SMTP SMTPS |
|
IMAP IMAPS |
|
POP3 POP3S |
|
TELNET TELNETS |
Les principaux avantages que peut procurer HTTPS par rapport à HTTP sont les suivants :
Cryptage des données.
Intégrité des données.
Confidentialité des données.
Garantie d’avoir un hôte récepteur de confiance.
Un système de détection d'intrusion (ou IDS : Intrusion Detection System) est un mécanisme destiné à repérer des activités anormales ou suspectes sur la cible analysée (un réseau ou un hôte). Il permet ainsi d'avoir une connaissance sur les tentatives réussies comme échouées des intrusions.
Il existe trois grandes familles distinctes d’IDS :
Les N IDS (Network Based Intrusion Detection System), qui surveillent l'état de la sécurité au niveau du réseau.
Les H IDS (HostBased Intrusion Detection System), qui surveillent l'état de la sécurité au niveau des hôtes.
Les IDS hybrides, qui utilisent les NIDS et HIDS pour avoir des alertes plus pertinentes.
N-IDS
Un N-IDS nécessite un matériel dédié et constitue un système capable de contrôler les paquets circulant sur un ou plusieurs lien(s) réseau dans le but de découvrir si un acte malveillant ou anormal a lieu. Le N-IDS place une ou plusieurs cartes d’interface réseau du système dédié en mode promiscuité (promiscuous mode), elles sont alors en mode « furtif » afin qu’elles n’aient pas d’adresse IP. Elles n’ont pas non plus de pile de protocole attachée. Il est fréquent de trouver plusieurs IDS sur les différentes parties du réseau et en particulier de placer une sonde à l'extérieur du réseau afin d'étudier les tentatives d'attaques ainsi qu'une sonde en interne pour analyser les requêtes ayant traversé le pare-feu ou bien menée depuis l'intérieur.
H-IDS
Le H-IDS réside
sur un hôte particulier et la gamme de ces logiciels couvre
donc une grande partie des systèmes d’exploitation tels
que Windows, Solaris, Linux, HP-UX, Aix, etc…
Le H-IDS se
comporte comme un démon ou un service standard sur un système
hôte. Traditionnellement, le H-IDS analyse des informations
particulières dans les journaux de logs (syslogs, messages,
lastlog, wtmp…) et aussi capture les paquets réseaux
entrant/sortant de l’hôte pour y déceler des
signaux d’intrusions (Déni de Services, Backdoors,
chevaux de troie, tentatives d’accès non autorisés,
exécution de codes malicieux, attaques par débordement
de buffeurs…).
Si les activités s’éloignent de la norme, une alerte est générée. La machine peut être surveillée sur plusieurs points :
Activité de la machine : nombre et listes de processus ainsi que d'utilisateurs, ressources consommées, ...
Activité de l'utilisateur : horaires et durée des connexions, commandes utilisées, messages envoyés, programmes activés, dépassement du périmètre défini...
Activité malicieuse d'un ver, virus ou cheval de Troie
Exemple d’IDS :
N-IDS : Snort, Bro
H-IDS : AIDE, Fheck
IDS hybride : Prelude
Le trafic réseau est généralement (en tout cas sur Internet) constitué de datagrammes IP. Un N-IDS est capable de capturer les paquets lorsqu’ils circulent sur les liaisons physiques sur lesquelles il est connecté. Un N-IDS consiste en une pile TCP/IP qui réassemble les datagrammes IP et les connexions TCP. Il peut appliquer les techniques suivantes pour reconnaître les intrusions :
Vérification de la pile protocolaire : Un nombre d’intrusions, tels que par exemple "Ping-Of-Death" et "TCP Stealth Scanning" ont recours à des violations des protocoles IP, TCP, UDP, et ICMP dans le but d’attaquer une machine. Une simple vérification protocolaire peut mettre en évidence les paquets invalides et signaler ce type de techniques très usitées.
Vérification des protocoles applicatifs : nombre d’intrusions utilisent des comportements protocolaires invalides, comme par exemple "WinNuke", qui utilise des données NetBIOS invalides (ajout de données OOB data). Dans le but de détecter efficacement ce type d’intrusions, un N-IDS doit ré-implémenter une grande variété de protocoles applicatifs tels que NetBIOS, TCP/IP, …
Cette technique est rapide (il n'est pas nécessaire de chercher des séquences d’octets sur l’exhaustivité de la base de signatures), élimine en partie les fausses alertes et s’avère donc plus efficiente. Par exemple, grâce à l’analyse protocolaire le N-IDS distinguera un événement de type « Back Orifice PING » (dangerosité basse) d’un événement de type « Back Orifice COMPROMISE » (dangerosité haute).
Reconnaissance des attaques par "Pattern Matching" : Cette technique de reconnaissance d’intrusions est la plus ancienne méthode d’analyse des N-IDS et elle est encore très courante.
Il s'agit de l’identification d’une intrusion par le seul examen d’un paquet et la reconnaissance dans une suite d’octets du paquet d’une séquence caractéristique d’une signature précise. Par exemple, la recherche de la chaîne de caractères « /cgi-bin/phf », qui indique une tentative d’exploit sur le script CGI appelé « phf ». Cette méthode est aussi utilisée en complément de filtres sur les adresses IP sources, destination utilisées par les connexions, les ports sources et/ou destination. On peut tout aussi coupler cette méthode de reconnaissance afin de l’affiner avec la succession ou la combinaison de flags TCP.
Cette technique est répandue chez les N-IDS de type « Network Grep » basé sur la capture des paquets bruts sur le lien surveillé, et comparaison via un parser de type « expressions régulières » qui va tenter de faire correspondre les séquences de la base de signatures octet par octet avec le contenu du paquet capturé.
L’avantage principal de cette technique tient dans sa facilité de mise à jour et évidemment dans la quantité importante de signatures contenues dans la base du N-IDS. Pourtant il n’a aucune assurance que quantité rime avec qualité. Par exemple, les 8 octets “CE63D1D2 16E713CF” quand ils sont disposés au début des données du protocole UDP indiquent du trafic Back Orifice avec un mot de passe par défaut. Même si 80% des intrusions utilisent le mot de passe configuré par défaut, les autres 20% utilisent des mots de passe personnalisés et ne seront absolument pas reconnus par le N-IDS. Par exemple, si l’on change le mot de passe de en "evade" alors la suite d’octets se transforme en "8E42A52C 0666BC4A", ce qui se traduira automatiquement par une absence de signalisation du N-IDS. Cette technique entraîne aussi inéluctablement un nombre important de fausses alertes ou faux positifs.
Les principales méthodes utilisées pour signaler et bloquer les intrusions sur les N-IDS sont les suivantes :
Reconfiguration d’équipement tierces (firewall, ACL sur routeurs) : Ordre envoyé par le N-IDS à un équipement tierce (filtreur de paquets, pare-feu) pour une reconfiguration immédiate dans le but de bloquer un intrus source d’intrusions. Cette reconfiguration est possible par passage des informations détaillant une alerte (en tête(s) de paquet(s)).
Envoi d’une trap SNMP à un hyperviseur tierce : Envoi de l’alerte (et le détail des informations la constituant) sous format d’un datagramme SNMP à une console tierce comme HP OpenView, Tivoli, Cabletron Spectrum, etc.
Envoi d’un e-mail à un ou plusieurs utilisateurs : Envoi d’un e-mail à une ou plusieurs boîtes au lettre pour notifier d’une intrusion sérieuse.
Journalisation (log) de l’attaque : Sauvegarde des détails de l’alerte dans une base de données centrale comme par exemple les informations suivantes: timestamp, @IP de l’intrus, @IP de la cible, protocole utilisé, payload).
Sauvegarde des paquets suspicieux : Sauvegarde de l’ensemble des paquets réseaux (raw packets) capturés et/ou seul(s) les paquets qui ont déclenchés une alerte.
Démarrage d’une application : Lancement d'un programme extérieur pour exécuter une action spécifique (envoi d’un message sms, émission d’une alerte auditive…).
Envoi d’un "ResetKill" : Construction d'un paquet TCP FIN pour forcer la fin d’une connexion (uniquement valable sur des techniques d’intrusions utilisant le protocole de transport TCP).
Notification visuelle de l’alerte : Affichage de l’alerte dans une ou plusieurs console(s) de management.
Un pare-feu est un élément du réseau informatique, logiciel et/ou matériel, qui a pour fonction de faire respecter la politique de sécurité du réseau, celle-ci définissant quels sont les types de communication autorisés ou interdits.
Le but ultime est de fournir une connectivité contrôlée et maîtrisée entre des zones de différents niveaux de confiance, grâce à l'application de la politique de sécurité et d'un modèle de connexion basé sur le principe du moindre privilège.
Le filtrage se fait selon divers critères. Les plus courants sont :
l'origine ou la destination des paquets (adresse IP, ports TCP ou UDP, interface réseau, etc.)
les options contenues dans les données (fragmentation, validité, etc.)
les données elles-mêmes (taille, correspondance à un motif, etc.)
les utilisateurs pour les plus récents
Différentes catégories de pare-feux :
Pare feux sans état (stateless firewall) : Il regarde chaque paquet indépendamment des autres et le compare à une liste de règles préconfigurées.
Pare feux avec état : notion de connexion ; vérifient que chaque paquet d'une connexion est bien la suite du précédent paquet et la réponse à un paquet dans l'autre sens ;
Pare feux applicatif : vérifie la complète conformité du paquet à un protocole attendu ; chaque application est gérée par un module différent exemple : countrack de Netfilter (Linux)
Pare feux identifiant : réalise l’identification des connexions passant à travers le filtre IP
Exemple de Firewall :
Linux Netfilter/Iptables, pare-feu libre des noyaux Linux 2.4 et 2.6.
Packet Filter ou PF, pare-feu libre de OpenBSD, importé depuis sur les autres BSD.
IPFilter ou IPF, pare-feu libre de BSD et Solaris 10.
Ipfirewall ou IPFW, pare-feu libre de FreeBSD.
NuFW Pare-feu identifiant sous licence GPL pour la partie serveur et les clients Linux, FreeBSD et Mac OS. NuFW est basé sur Netfilter et en augmente les fonctionnalités.
iSafer, pare-feu libre pour Windows.
SSL abrégé de Secure Sockets Layers est un standard permettant de sécuriser des transactions qui a été développé par Netscape en collaboration avec des sociétés tel quel Bank of America.
Le principe repose sur un procédé cryptographique par clefs publiques de type asymétrique qui procure une plus grande sécurité.
Ce protocole travaille au niveau de la couche de transport (niveau 4) dans le modèle OSI.
Plusieurs versions de SSL existent:
SSL2: authentification du serveur + confidentialité des échanges.
SSL3: SSL2 avec en plus l'authentification mutuelle (client/serveur) + contrôle d'intégrité. Un dérivé de cette version par l'IETF se nomme TLS.
SSL est basé sur l'utilisation de certificat utilisant différents algorithmes cryptographiques tel que :
Chiffrement : DES, 3DES, RC2, RC4, AES
Hachage : MD5, SHA
Signature : RSA
Les étapes SSL :
Le client se connecte au serveur indique la version de SSL qu'il utilise.
Le serveur répond à son tour avec ses informations.
Le client peut vérifier auprès d'une autorité tierce pour savoir si c'est réellement le serveur avec qui il communique.
Le client s'authentifie auprès du serveur qui vérifie par l'intermédiaire du certificat du client.
Les échanges de certificat qui comprend la clé de session commencent.
Arrivé à ce stade nous avons un réseau de confiance opérationnel entre 2 entités. Les échanges de messages chiffrés et signés peuvent commencer.
A la fin de communication, les clés sont détruites.

Figure 22 : Architecture client/serveur/tiers de certification pour SSL
Le lieu de stockage intermédiaire des différentes données en vue de la constitution du système d'information décisionnel est appelé entrepôt de données (en anglais datawarehouse).
Le datawarehouse est ainsi le lieu unique de consolidation de l'ensemble des données de l’entreprise. Le créateur du concept de DataWareHouse, Bill Inmon, le définit comme suit :
« Un datawarehouse est une collection de données thématiques, intégrées, non volatiles et historisées pour la prise de décisions. »
Ses principales caractéristiques sont donc les suivantes :
Le datawarehouse est orienté sujets, cela signifie que les données collectées doivent être orientées « métier » et donc triées par thème
Le datawarehouse est composé de données intégrées, c'est-à-dire qu'un « nettoyage » préalable des données est nécessaire dans un souci de rationalisation et de normalisation
Les données du datawarehouse sont non volatiles ce qui signifie qu'une donnée entrée dans l'entrepôt l'est pour de bon et n'a pas vocation à être supprimée
Les données du datawarehouse doivent être historiées, donc datées
|
Caractéristique |
Base de données |
Entrepôt de données |
|
Opération |
gestion courante, production |
analyse, support à la décision |
|
Modèle de données |
entité/relation |
étoile, flocon de neige |
|
Normalisation |
Fréquente |
plus rare |
|
Données |
actuelles, brutes |
historiées, parfois agrégées |
|
Mise à jour |
immédiate, temps réel |
souvent différée |
|
Niveau de consolidation |
Faible |
Elevé |
|
Perception |
Bidimensionnelle |
multidimensionnelle |
|
Opérations |
lectures, mises à jour, suppressions |
lectures, analyses croisées, rafraîchissements |
|
Taille |
en gigaoctets |
en téraoctets |
Ces différences tiennent au fait que les entrepôts permettent des requêtes qui peuvent être complexes et qui ne reposent pas nécessairement sur une unique table.
Exemples de requêtes OLAP :
Quel est le nombre de paires de chaussures vendues par le magasin "OnVendDesChaussuresIci" en mai 2003 ET Comparer les ventes avec le même mois de 2001 et 2002
Quelles sont les composantes des machines de production ayant eu le plus grand nombre d’incidents imprévisibles au cours de la période 1992-97 ?
Le terme Datamart (littéralement magasin de données) désigne un sous-ensemble du datawarehouse contenant les données du datawarehouse pour un secteur particulier de l'entreprise (département, direction, service, gamme de produit, etc.). On parle ainsi par exemple de DataMart Marketing, DataMart Commercial, ...
Qu'est ce que la virtualisation d'un serveur. Citez les deux architectures possibles, avantages et inconvénients ?
Définition de la virtualisation : Ensemble des techniques matérielles et/ou logicielles qui permettent de faire fonctionner sur une seule machine plusieurs systèmes d‘exploitation et/ou plusieurs applications, séparément les uns des autres, comme s'ils fonctionnaient sur des machines physiques distinctes.
Listes des avantages de la virtualisation :
La virtualisation permet d’augmenter le taux d’utilisation des ressources physiques, on évite ainsi les serveurs surdimensionnés par rapport à leur utilisation, on rentabilise ainsi plus des ressources chères. Il faut cependant bien entendu prendre en compte les pics d’utilisation et bien répartir les machines virtuelles pour avoir un service équivalent à un serveur classique.
La virtualisation permet de réduire le nombre de serveurs physiques, ce qui implique également un gain en terme de place dans les salles serveurs, en consommation électrique, de climatisation…
Enfin, la virtualisation permet la consolidation d’anciens systèmes. Les anciens systèmes comme Windows NT4 ne peuvent plus fonctionner que sur d’anciennes machines car les pilotes matériels n’existent plus. Une méthode pour consolider ces systèmes et d’utiliser la virtualisation et ainsi s’affranchir du matériel, même si bien sûr il est conseillé de migrer vers des solutions plus récentes.
Exemples : Xen, Microsoft Virtual Server, VMWare Infrastructure
Virtualisation utilisant un système hôte
Cette technique consiste à installer un logiciel permettant la virtualisation sur un système d’exploitation (Windows, Linux…). Ce logiciel de virtualisation crée une couche d’abstraction du matériel de la machine physique et permet la création de plusieurs machines virtuelles.
Figure 22 : Architecture de la virtualisation utilisant un logiciel
Comme le montre le schéma ci-dessus, le logiciel de virtualisation fait partie de l’ensemble des applications installées sur le système d’exploitation hôte. Il permet de lancer des machines virtuelles qui auront un comportement indépendant entre elles. Ce système est utilisé sur des stations de travail clientes, permettant souvent de lancer différents environnements pour des besoins de développement et de tests. Il est très peu adapté dans le cas d’une utilisation serveur car la gestion des ressources n’est pas optimale et la stabilité de l’ensemble du système dépend de celle du système hôte.
Virtualisation utilisant un système dédié (hyperviseur)
Cette technologie n’utilise plus un système hôte classique comme précédemment mais un système d’exploitation dédié à la virtualisation. Ce système est beaucoup plus léger qu’un système d’exploitation classique et est optimisé pour la virtualisation. Il ne peut être utilisé pour une autre activité, seules des machines virtuelles peuvent être installées dessus.
Figure 22 : Architecture de virtualisation par système dédié
Comme le montre le schéma ci-dessus, le système d’exploitation dédié à la virtualisation crée directement une couche d’abstraction du matériel physique de la machine et permet le lancement de plusieurs machines virtuelles. Cette solution est plus adaptée à une utilisation serveur, le système étant plus léger (donc moins consommateur en ressources) et optimisé pour la virtualisation.
NAS : Network Attached Storage
Désigne un périphérique de stockage relié à un réseau dont la principale fonction est le stockage de données en un gros volume centralisé pour des clients réseaux hétérogènes. Le serveur NAS a pour vocation d'être accessible depuis des serveurs client à travers le réseau pour y stocker des données.
La gestion centralisée sous forme de fichiers à plusieurs avantages :
faciliter la gestion des sauvegardes des données d'un réseau
prix intéressant des disques grandes capacités par rapport à l'achat de disques en grand nombre sur chaque serveur du réseau
accès par plusieurs serveurs clients aux mêmes données stockées sur le NAS
réduction du temps d'administration des serveurs clients en gestion d'espace disques
Le NAS peut s'intégrer ou être le point d'entrée d'un SAN.
DAS : Direct Attached Storage
Se dit d’un système de stockage où les disques sont directement attachés à l’unité qui les utilise (ordinateur, serveur), par opposition aux NAS et aux SANs.
SAN : Storage Area Network
Réseau spécialisé rapide (Fibre Channel) entre différentes machines, uniquement dédié à l’accès aux données de manière logique, alors qu’elles peuvent être réparties sur plusieurs supports physiques. Il apporte des fonctionnalités de sauvegarde et de reprise puissantes.
La virtualisation, c'est la mise en commun logique d'éléments de stockage qui étaient indépendants à l'origine. On peut rassembler dans un stockage virtuel des éléments dissemblables (DAS, NAS, SAN...), provenant de constructeurs différents et utilisant des protocoles de gestion de fichiers différents.
Les avantages de la virtualisation sont :
regroupement des surfaces libres minimales par application ou support dans un espace global plus petit (donc économie),
possibilité de disposer immédiatement d'une nouvelle surface libre devenue soudain nécessaire,
possibilité de basculer d'un support physique sur un autre (en cas de panne, par exemple),
éventuellement, amélioration des performances (optimisation besoins/ressources rapides),
enfin, c'est aussi une façon de regrouper des matériels hétérogènes (constructeurs, normes...).
Virtualisation symétrique, ou in-band :
Il s'agit d'une architecture classique dans laquelle les serveurs applicatifs envoient leurs données et reçoivent leurs données d'un serveur de virtualisation central. Celui-ci assure la gestion des espaces de stockage. Toutes les données transitent par lui. Les serveurs applicatifs ont l'impression d'accéder directement aux systèmes de stockage et il est généralement inutile de modifier les pilotes.
Virtualisation asymétrique, ou out-band :
Pour éviter des "bouchons" au niveau du serveur de virtualisation, les données ne transitent pas par lui, mais directement du serveur applicatif à l'espace de stockage assigné. Pour assurer la gestion, le serveur de virtualisation possède sur chaque serveur applicatif des agents à qui il transmet ses instructions et qui lui indiquent en retour les espaces utilisés.
Wide Area File Services ; Serveur de cache de données installées dans les sites distants pour prolonger à distance un NAS central. Une technologie, utilisée principalement dans les entreprises ayant des succursales distribuées géographiquement, qui permet d'optimiser les accès distants à un serveur de fichiers central au travers d'un réseau étendu (WAN).
Les objectifs de la sécurité informatique sont :
L'intégrité, c'est-à-dire garantir que les données, les traitements, les services n’ont pas été altérés, modifiés ou détruit tant de façon intentionnelle qu’accidentelle ;
La confidentialité, consistant à assurer que seules les personnes autorisées aient accès aux ressources échangées (protection par mot de passe ou chiffrement) ; non divulgation aux personnes non autorisés
La disponibilité, permettant de maintenir le bon fonctionnement du système d'information ;
La non répudiation, permettant de garantir qu'une transaction ne peut être niée ; mise en place de journaux pour qu’à chaque action un enregistrement, une preuve existe.
De façon générale les moyens mis en ouvre pour protéger un système informatique sont :
La sensibilisation des utilisateurs aux problèmes de sécurité
La sécurité logique, c'est-à-dire la sécurité au niveau des données, notamment les données de l'entreprise, les applications ou encore les systèmes d'exploitation.
La sécurité des télécommunications : technologies réseau, serveurs de l'entreprise, réseaux d'accès, etc.
La sécurité physique, soit la sécurité au niveau des infrastructures matérielles : salles sécurisées, lieux ouverts au public, espaces communs de l'entreprise, postes de travail des personnels, etc.

Figure 22 : Sécurité d'un système informatique
Il est ainsi possible de catégoriser les risques de la manière suivante :
Accès physique : il s'agit d'un cas où l'attaquant à accès aux locaux, éventuellement même aux machines :
Coupure de l'électricité
Extinction manuelle de l'ordinateur
Vandalisme
Ouverture du boîtier de l'ordinateur et vol de disque dur
Ecoute du trafic sur le réseau
Réplique : sécurité générale et de fonctionnement
protection de l’environnement immédiat : caméra, ronde de personnel ;
protection des locaux : badges, sas d’accueil, télésurveillance, compartiments ;
protection des personnels : habilitation, surveillance des personnes de passage, pas de visiteur non accompagné ;
protection incendie, électrique ; climatisation ; dégât des eaux ; pannes de matériel
Ingénierie sociale : Dans la majeure partie des cas le maillon faible est l'utilisateur lui-même ! En effet c'est souvent lui qui, par méconnaissance ou par duperie, va ouvrir une brèche dans le système, en donnant des informations (mot de passe par exemple) au pirate informatique ou en exécutant une pièce jointe. Ainsi, aucun dispositif de protection ne peut protéger l'utilisateur contre les arnaques, seul bon sens, raison et un peu d'information sur les différentes pratiques peuvent lui éviter de tomber dans le piège !
Interception de communications :
Vol de session (session hijacking)
Usurpation d'identité
Détournement ou altération de messages
Dénis de service : il s'agit d'attaques visant à perturber le bon fonctionnement d'un service. On distingue habituellement les types de déni de service suivant :
Exploitation de faiblesses des protocoles TCP/IP
Exploitation de vulnérabilité des logiciels serveurs
Intrusions :
Balayage de ports
Elévation de privilèges : ce type d'attaque consiste à exploiter une vulnérabilité d'une application en envoyant une requête spécifique, non prévue par son concepteur, ayant pour effet un comportement anormal conduisant parfois à un accès au système avec les droits de l'application. Les attaques par débordement de tampon (en anglais buffer overflow) utilisent ce principe.
Maliciels (virus, vers et chevaux de Troie
Trappes : il s'agit d'une porte dérobée (en anglais backdoor) dissimulée dans un logiciel, permettant un accès ultérieur à son concepteur.
Un virus est un petit programme informatique situé dans le corps d'un autre, qui, lorsqu'on l'exécute, se charge en mémoire et exécute les instructions que son auteur a programmées. La définition d'un virus pourrait être la suivante :
« Tout programme d'ordinateur capable d'infecter un autre programme d'ordinateur en le modifiant de façon à ce qu'il puisse à son tour se reproduire. »
Les virus résidents se chargent dans la mémoire vive de l'ordinateur afin d'infecter les fichiers exécutables lancés par l'utilisateur. Les virus non résidants infectent les programmes présents sur le disque dur dès leur exécution.
Les virus ne sont pas classés selon leurs dégâts mais selon leur mode de propagation et d'infection.
On distingue ainsi différents types de virus :
Les vers sont des virus capables de se propager à travers un réseau
Les chevaux de Troie (troyens) sont des virus permettant de créer une faille dans un système (généralement pour permettre à son concepteur de s'introduire dans le système infecté afin d'en prendre le contrôle)
Les bombes logiques sont des virus capables de se déclencher suite à un événement particulier (date système, activation distante, ...)
Depuis quelques années un autre phénomène est apparu, il s'agit des canulars (en anglais hoax), c'est-à-dire des annonces reçues par mail (par exemple l'annonce de l'apparition d'un nouveau virus destructeur ou bien la possibilité de gagner un téléphone portable gratuitement) accompagnées d'une note précisant de faire suivre la nouvelle à tous ses proches. Ce procédé a pour but l'engorgement des réseaux ainsi que la désinformation.
Si on les classe par rapport à la signature virale :
Le virus mutant : clone d’un virus dont la signature à été modifier.
Le virus polymorphe : virus capable de modifier sa signature ; généralement par chiffrement
Rétrovirus : virus capable de modifier la base de signature d’un antivirus afin de le rendre inopérant.
Les différentes techniques de recherche de virus sont :
La recherche de signature virale : suite d’octet permettant au virus et à fortiori aux antivirus de se reconnaître. Les virus s’en servent pour détecter si un programme est déjà infecté ou non.
Le contrôle d’intégrité : l’antivirus réalise au préalable une base de données des codes de contrôles des binaires du système afin de les contrôler régulièrement. Un changement dans le code de contrôle indique une modification du code du binaire, de son intégrité et donc une infection.
Le contrôle de comportement des programmes : compare le comportement de chaque programme avec une base de donnée de comportement connu. Permet de détecter des virus sans pour autant les connaître mais peut déclencher pas mal de fausse alerte.
C’est une attaque de programme informatique dites par « débordement de tampon » (en anglais « Buffer overflow », parfois également appelées dépassement de tampon), elle a pour principe l'exécution de code arbitraire par un programme en lui envoyant plus de données qu'il n'est censé en recevoir.
La cryptographie permet de satisfaire les besoins de sécurité suivant :
La confidentialité, l’authenticité, l’authentification
La non répudiation
L’intégrité
Différence de performance : les opérations de chiffrement asymétrique (opération de codage et de décodage) sont plus gourmandes en ressources que celle de chiffrement symétriques. Exemple RSA est par exemple 1000 fois plus lent que DES
La confidentialité des clés : Le chiffrement asymétrique autorise la diffusion en claire de la clé de cryptage de message.
Le nombre de clé : Alors que le chiffrement symétrique n’utilise qu’une seule clé pour chiffrer et déchiffrer, le chiffrement asymétrique nécessite deux clés différentes (d’où l’asymétrie) : une pour déchiffrer la clé privée et l’autre qui permet de chiffrer et qui est diffusée.
Les certificats sont le plus souvent utilisés dans les systèmes asymétriques pour garantir la clé publique.
Les clés
publiques sont généralement partagées à
l'aide d'annuaire électronique (généralement au
format LDAP) ou d'un site Web. Malheureusement, un pirate peut tout à
fait substituer la clé publique d'une personne à la
sienne et ainsi lire tous les messages cryptés à l'aide
de sa clé privée correspondante. Le problème est
donc de garantir que la clé est bien celle de l'utilisateur à
qui elle est associée. Pour résoudre ce problème,
nous utilisons des certificats d'authenticité délivrés
par des organismes indépendants appelés autorité
de certification. Pour que le certificat soit régulièrement
contrôlé, il est délivré avec une date de
validité comme pour les cartes bancaires. Ainsi, l'organisme
délivreur re-contrôle tous les ans les certificats de
ses clients pour garantir une meilleure authenticité.
Infrastructure à clé publiques ; c’est application des certificats pour gérer l'authentification et la signature numérique d'une entité.
Exemple un serveur web (Apache avec le module SSL par exemple), ou simplement un client souhaitant signer et chiffrer des informations à l'aide de son certificat de la façon décrite dans les sections précédentes.
De quoi est
composé un certificat ?
Un certificat est un fichier
divisé en deux parties contenant
les informations
la signature de l'autorité de certification
Les informations contenues dans le certificat sont
le nom de l'autorité de certification
le nom du propriétaire du certificat
la date de validité du certificat
l'algorithme de chiffrement utilisé
la clé publique du propriétaire
L'ensemble de ces
informations est signé par l'autorité en créant
une empreinte avec une fonction de hachage qui est ensuite cryptée
avec la clé privée de l'autorité de
certification. Sa clé publique est quand à elle très
largement diffusée pour permettre à n'importe quel
utilisateur de vérifier la signature du certificat.
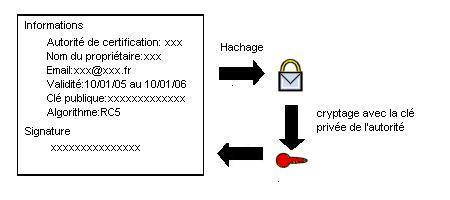
Figure 22 : Procéder d'élaboration de la signature d'un certificat
Pour vérifier le certificat, l'utilisateur applique la fonction de hachage aux informations et décrypte la signature à l'aide de la clé publique de l'autorité de certification. Si les deux sont équivalentes alors le certificat est correct.
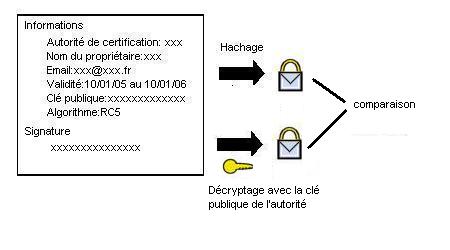
Figure 22 : Procéder de vérification de la signature d'un certificat
Le chiffrement à clé symétrique
Aussi appelé algorithme à clé secrète ; leur caractéristique la plus importante de cette méthode est qu'une seule clé sert à coder et à décoder le message.
Le problème de cette technique est que la clé, qui doit rester totalement confidentielle, doit être transmise au correspondant de façon sûre.
Exemples historiques : ROT13, Enigma
Exemples contemporains : DES, AES, RC4, RC5
Le chiffrement à clé asymétrique
Aussi appelé chiffrement à clé publique ; nécessite 2 clés générées en même temps et qui présentent l’avantage de pouvoir diffuser (échanger) en claire la clé qui sert à crypter le message.
Une clé privée sert à décoder le message ; clé secrète connue exclusivement par son propriétaire.
Une clé publique sert à coder le message ; clé publique diffusé largement (diffusion par annuaire genre LDAP).
La cryptographie asymétrique est également utilisée pour assurer l'authenticité d'un message. L'empreinte du message est chiffrée à l'aide de la clé privée et est jointe au message. Les destinataires déchiffrent ensuite le cryptogramme à l'aide de la clé publique et retrouvent normalement l'empreinte. Cela leur assure que l'émetteur est bien l'auteur du message. On parle alors de signature ou encore de scellement.
Principale inconvénient : leur lenteur par rapport au chiffrement symétrique. Exemple RSA est par exemple 1000 fois plus lent que DES.
Exemple : RSA, DSA, Diffie-Hellman
Combinaison usage de clé symétrique et asymétrique
Dans le système combiné, une clé symétrique est utilisée pour coder et décoder le message mais cette clé symétrique est cryptée de façon asymétrique avant d'être transmise.
Exemple : PGP, GPG (Verion GNU de PGP)
Une fonction de hachage est une fonction qui convertit un grand ensemble en un plus petit ensemble, aussi appelé : l'empreinte. Une fonction de hachage permet d'obtenir un condensé d'un message de manière unique et dans un seul sens. Autrement dit, il est impossible de la déchiffrer pour revenir à l'ensemble d'origine, ce n'est donc pas une technique de chiffrement.
L'empreinte d'un message ne dépasse généralement pas 256 octets et permet de vérifier son intégrité.
Exemple : MD5, SHA-1
DES
Système de
chiffrement par bloc de 64 bits ; Cet algorithme repose
sur des opérations de combinaisons, substitutions et
permutations entre le texte à chiffrer et la clé.
Ces opérations ont la particularité de pouvoir être
faites dans les deux sens (pour le déchiffrement).
Ces
opérations se déroulent ainsi
Fractionnement du texte en blocs de 64 bits (8 octets)
Permutation initiale des blocs
Découpage des blocs en deux parties: gauche et droite, nommées G et D
Etapes de permutation et de substitution répétées 16 fois (appelées rondes)
Recollement des parties gauche et droite puis permutation initiale inverse
AES
L'algorithme AES n'est
pas basé sur la même structure que celui de DES. En
effet, il s'appuie sur Rijndael qui est un algorithme de chiffrement
par bloc, avec plusieurs tours. Sa longueur de bloc et sa longueur de
clé sont variables allant de 128, 192 à 256 bits
(contre 56 pour le DES).
La clé et les blocs sont
représentés sous forme d'une matrice de 4 lignes et
d'un nombre de colonne variable selon la longueur de la clé
divisée par 32, soit 4, 6 ou 8 colonnes. Cette matrice est
appelée « état » au cours des différentes
itérations.
Au premier tour, on remplit l'état avec
les données du bloc, et on fait de même pour la clé.
Le nombre de tours dépend de la longueur du bloc et de la clé.
A chaque tour, quatre transformations différentes sont
effectuées, sauf pour le dernier où seulement trois
sont effectuées.
Ce nouveau mode a l'avantage d'être
peu gourmand en mémoire, simple et rapide à exécuter.
Diffie-Hellman
Cet algorithme inventé
en 1976 est le plus ancien cryptosystème à clé
publique mais reste néanmoins le plus utilisé.
Ses
atouts sont:
Générer une clé sans échange d'informations au préalable.
Ne réaliser aucune authentification.
Reposer sur des logarithmes discrets (difficile à calculer) pour accroître la sécurité.
RSA
Cet algorithme fut
inventé en 1977 et porte les initiales de ses inventeurs.
Sa
sécurité réside en la difficulté de
factoriser des grands nombres. En effet, nous savons qu'un nombre
entier est égal au produit de nombres premiers. Il est alors
facile de retrouver ce produit en revanche trouver les facteurs
premiers d'un grand nombre est une opération très
difficile (aucune rapide n'est connue à ce
jour).
Principe
Constitution de la
clé publique:
Deux grands nombres premiers (entre 150 et
200 chiffres) p et q sont choisis. Nous calculons n=p*q.
Ensuite,
nous choisissons e tel que e et (p-1)(q-1) soient premiers entre
eux.
e et n constitue la clé publique.
Constitution de la
clé privée:
d = e^(-1) (mod (p-1)(q-1)).
d
consitue la clé privée.
Chiffrement:
Soit
m, un message de longueur variable, il faut découper m en
bloc de taille inférieure à n (pour que chaque bloc
n'est qu'une seule représentation possible modulo n). Pour
chaque bloc mi on calcule :
Ci = mi^e mod n
Déchiffrement:
Mi
= ci^d mod n
MD5
Le MD5 (Message Digest
version 5) est une fonction de hachage qui fournit une empreinte de
128 bits.
Son principe est de manipuler des blocs de 512 bits.
Pour cela, il complète la longueur du message par un 1 suivi
d'autant de 0 que nécessaires pour arriver une longueur
congrue à 448 modulo 512. Cette opération s'appelle
"padding" et à toujours lieu.
Ensuite, la
longueur initiale du message est ajoutée aux 448 bits. La
taille finale est donc un multiple de 512 bits. On découpe
ensuite chaque bloc de 512 bits en 16 blocs de 32 bits qui seront
passés aux 4 fonctions.
On définit 4 buffers de 32
bits A, B, C et D, initialisés ainsi en hexadécimal
A=01234567
B=89abcdef
C=fedcba98
D=76543210
On définit aussi 4 fonctions F,G,H et I, qui prennent des arguments codés sur 32 bits, et renvoie une valeur sur 32 bits, les opérations se faisant bit à bit.
F(X,Y,Z) = (X AND Y) OR (not(X) AND Z)
G(X,Y,Z) = (X AND Z) OR (Y AND not(Z))
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X OR not(Z))
Pour chaque bloc de
512 bits du texte, on fait les opérations suivantes
on sauvegarde les valeurs des registres dans AA, BB, CC, DD.
on calcule de nouvelles valeurs pour A, B, C, D à partir de leurs anciennes valeurs, à partir des bits du bloc qu'on étudie, et à partir des 4 fonctions F, G, H, I.
on fait A=AA+A, B=BB+B, C=CC+C, D=DD+D.
Le résultat
sur 128 bits est obtenu en mettant bout à bout les 4 buffers
A, B, C, D de 32 bits pour chaque bloc de 512 bits constituant le
message.
Couplage Téléphonie-Informatique ; Ensemble des techniques permettant la mise en oeuvre d'applications reposant sur un inter fonctionnement d'applicatifs informatiques et d'applicatifs téléphoniques.
Ce dispositif reliant un centre d'appel interne ou externe au système informatique d'une entreprise, apporte aux sociétés l'opportunité d'utiliser les ressources du système d'information et d'Internet, afin d'améliorer le service rendu aux clients et la productivité d'un centre d'appels.
Ceci est rendu possible par l'automatisation de certaines tâches et la possibilité d'instaurer une personnalisation poussée de la relation avec le client via les informations mises à disposition par ce système.
Il rend possible l'affichage simultané sur l'écran du télé-opérateur de données (fiche du client et script de l'entretien) ainsi que la présentation de l'appel sur son poste téléphonique. Par exemple, l'identification d'un numéro de téléphone permettra de retrouver les informations concernant l'appelant pendant que l'appel est transféré au bon interlocuteur. La composition automatique de numéros à partir d'une liste d'adresse constitue une autre application.
Avantages
Qualité de service : Améliorer l'accueil de la clientèle en permettant aux services téléphoniques de tirer parti de la rapidité et de la souplesse de l'informatique.
Productivité : Optimiser l'efficacité des employés des services clients, en permettant le couplage des deux principaux outils de bureau que sont le téléphone et l'ordinateur.
Economies : Gagner sur les coûts par la réduction du temps des appels et la productivité induite.
Description du fonctionnement
Le CTI est en fait le
lien entre le Serveur d’application et le PABX (Private
Automatic Branch eXchange ou Autocommutateur). Le concept est le
suivant :
L’application du PC agit
en envoyant des commandes au PABX, celui-ci effectue le traitement et
renvoie le résultat que la commande ait échoué
ou pas.

Figure 22 : Architectre de CTI constitué d'un PABX et d'un serveur d'application téléphonique
Tout
cela se passe via une API (Application Programming Interface) qui
utilise un protocole standard permettant la communication entre le
PABX et le PC.
On peut faire cette liaison de 2 manières :
Contrôle direct : C’est la liaison la plus facile à mettre en place. Cette liaison associe directement le téléphone et l’ordinateur. Mais, de cette manière, il n’y a que l’ordinateur connecté au téléphone qui a le droit de le contrôler. Ce qui permet à l’ordinateur de contrôler certaines fonctionnalités du téléphone normalement à la charge de l’utilisateur.

Figure 22 : Architecture CTI en contrôle direct
Contrôle indirect : Cette liaison est plus complexe à implémenter et requiert souvent un serveur d’application téléphonique dédié. Celui-ci aura pour seule utilité l’interfaçage entre le réseau téléphonique et le réseau informatique. De cette manière, chaque ordinateur du réseau peut contrôler un téléphone quelconque du réseau téléphonique relié au serveur. L’étape ultime est la fusion du réseau téléphonique et informatique grâce au LAN-PBX et à la voix sur IP.

Figure 22 : Architecture CTI en contrôle indirect
Les applications
Service vocale interactif : services de transaction (réservations, télépaiement, ...) et les services de consultation (horaires, comptes bancaires, ...) ou encore de standard automatique
Automate d’appel : A partir d’une base de donnée associé et du numéro d’appel met en liaison avec une opérateur libre tout en faisant remonté une fiche d’information associé
Le distributeur automatique d’appel : choisit le chemin que va prendre l’appel avant que l’agent ne lui réponde. L’ACD gère tous les appels entrant et distribue selon une configuration prédéfinie les appels aux agents concernés. Suivant l’occupation des agents, l’appel va transiter différemment et va être mis en attente en cas d’occupation de tous les agents jusqu’à ce que l’un d’entre eux devienne disponible. Il peut également fournir des statistiques sur les flux d’appel, sur le nombre d’appels gérés par chaque agent
Le télémarkéting : gérer en temps réel le déroulement des campagnes en proposant aux téléacteurs et au superviseur des guides sur écran et d'un support de saisie au clavier des réponses.
Private Automatic Branch Exchange
Autocommutateur ou standard téléphonique
Certains langages appartiennent en quelque sorte aux deux catégories (LISP, Java, Python, ..) car le programme écrit avec ces langages peut dans certaines conditions subir une phase de compilation intermédiaire vers un fichier écrit dans un langage qui n'est pas intelligible (donc différent du fichier source) et non exécutable (nécessité d'un interpréteur).
Exemples : applet JAVA
Un langage impératif organise le programme sous forme d'une série d'instructions, regroupées par blocs et comprenant des sauts conditionnels permettant de revenir à un bloc d'instructions si la condition est réalisée. Il s'agit historiquement des premiers langages, même si de nombreux langages modernes utilisent toujours ce principe de fonctionnement.
Les langages impératifs structurés souffrent néanmoins d'un manque de souplesse étant donné le caractère séquentiel des instructions.
Un langage fonctionnel (parfois appelé langage procédural) est un langage dans lequel le programme est construit par fonctions, retournant un nouvel état en sortie et prenant en entrée la sortie d'autres fonctions. Lorsque la fonction s'appelle elle-même, on parle alors de récursivité.
Un langage assertionnel doit permettre de décrire le résultat sans spécifier l'ordre d'exécution des différentes opérations. C’est un langage fondé sur la logique des prédicats et sur le modèle relationnel. C’est un langage ensembliste. Il permet de spécifier ce que l'on souhaite obtenir sans dire comment l'obtenir.
Un programme écrit dans un langage interprété a besoin d'un programme auxiliaire (l'interpréteur) pour traduire au fur et à mesure les instructions du programme.
Un programme écrit dans un langage dit « compilé » va être traduit une fois pour toute par un programme annexe, appelé compilateur, afin de générer un nouveau fichier qui sera autonome, c'est-à-dire qui n'aura plus besoin d'un programme autre que lui pour s'exécuter; on dit d'ailleurs que ce fichier est exécutable.
Un programme compilé n’a plus besoin d’un programme annexe pour s’exécuter, il est plus rapide à l’exécution, moins souple car doit être recompilé à chaque modification du code source, plus dur à comprendre car en binaire.
Se dit d'un type de programmation, fondé sur les événements. Le programme sera principalement défini par ses réactions aux différents événements qui peuvent se produire.
1er génération : programme écrit dans un langages directement exécutable par un processeur. Ex langage machine.
2eme génération : plus proche du langage parlé. Ex : assembleur.
3eme génération : langage plus proche du langage parlé :
Ex : langage procédural (Pascal, langage C) ; langage objet (Smalltalk, java)
4ème Génération : fabrication de code à partir de l’expression de la solution utilisé Ex : Designer visuel (Visual Basic, Visual C++, Neatbeans)
Un Framework est un ensemble structuré de services (API) à disposition d’un programme pour un système d’exploitation donnée.
Exemple : Framework DotNet de Microsoft

le compilateur transforme le code source en code objet, et le sauvegarde dans un fichier objet, c'est-à-dire qu'il traduit le fichier source en langage machine (certains compilateurs créent aussi un fichier en assembleur, un langage proche du langage machine car possédant des fonctions très simples, mais lisibles)
le compilateur fait ensuite appel à un éditeur de
liens (en anglais linker ou binder) qui permet
d'intégrer dans le fichier final tous les éléments
annexes (fonctions ou librairies) auquel le programme fait référence
mais qui ne sont pas stockés dans le fichier source.
Puis
il crée un fichier exécutable qui contient tout
ce dont il a besoin pour fonctionner de façon autonome.
Un exécutable compilé en statique se suffit à lui-même lors de son exécution. Il contient dans son code le corps de fonctions auxquelles il fait référence et à fortiori n’utilise pas de librairies partagées lors de son exécution. Par conséquent, il est d’une taille plus importante que le même programme compilé en dynamique.
Un exécutable compilé en dynamique réalise l’édition des liens (correspondance entre une fonction et l’adresse mémoire contenant le code de son corps) lors de l’exécution du programme en mémoire. C’est le système d’exploitation qui tente de résoudre la dépendance du programme avec les libraires (nom + version).
En mode « Debug » les informations suivantes sont rajoutées dans le fichier :
Le numéro de ligne du code source correspondant à instruction exécutable pour suivre le programme pas à pas ou pour afficher le numéro de ligne de la dernière instruction exécutée;
Une table avec l’adresse de chaque variable du programme pour accéder à son contenu ;
CVS ou Subversion : pour le gestion de version
IDE (Integrated Environement Development) : eclipse, Netbeans, Visual Studio
AGL : Atelier de Génie Logiciel (Rationnal Rose)
Documents de conception fourni par l’analyste programmeur : Cahier des charges pour les tests
C’est un programme qui n’utilise que des variables locales.
Un débogueur (en anglais, debugger) est un logiciel qui permet de déboguer, c'est-à-dire d'aider le programmeur à détecter des bogues dans un programme (il peut aussi servir à tester ce dernier).
Le programme à déboguer est exécuté à travers le débogueur et s'exécute normalement. Le débogueur offre alors au programmeur la possibilité de contrôler l'exécution du programme, en lui permettant par divers moyen de stopper (mettre en pause l'exécution du programme) et d'observer par exemple le contenu des différentes variables en mémoire. L'état d'exécution peut alors être observé afin, par exemple, de déterminer la cause d'une défaillance.
Quand l'exécution d'un programme est stoppée, le débogueur affiche la position courante d'exécution dans le code source original si celui-ci est un source-level debugger ou symbolic debugger. Si c'est un low-level debugger ou un machine-language debugger, il montre la ligne désassemblée.
De nombreux debogueurs permettent, en plus de l'observation de l'état des registres processeurs et de la mémoire, de les modifier avant de rendre la main au programme débogué. Ils peuvent alors être utilisés pour localiser certaines protections logicielles et les désactiver, amenant à la conception d'un crack. Ainsi, certains logiciels, connaissant le fonctionnement des débogueurs et voulant empêcher de telles modifications, mettent en place des techniques antidébogage (anti debugging tricks)
Exemple : Gdb, Windbg, Purify, Valgrind
En programmation orientée objet, une classe déclare des propriétés communes à un ensemble d'objets. La classe déclare des attributs représentant l'état des objets et des méthodes représentant leur comportement.
Une classe représente donc une catégorie d'objets. Il apparaît aussi comme un moule ou une usine à partir de laquelle il est possible de créer des objets. On parle alors d'un objet en tant qu'instance d'une classe (création d'un objet ayant les propriétés de la classe).
Il est possible de restreindre l'ensemble d'objets représenté par une classe A grâce à un mécanisme d'héritage. Dans ce cas, on crée une nouvelle classe B liée à la classe A et qui ajoute de nouvelles propriétés. Dans ce cas, différents termes sont utilisés :
A est une généralisation de B et B est une spécialisation de A,
A est une super-classe de B et B est une sous-classe de A,
A est la classe mère de B et B est une classe fille de A.
Le polymorphisme est l'idée d'autoriser le même code à être utilisé avec différents types, ce qui permet des implémentations plus abstraites et générales.
En proposant d'utiliser un même nom de méthode pour plusieurs types d'objets différents, le polymorphisme permet une programmation beaucoup plus générique. Le développeur n'a pas à savoir, lorsqu'il programme une méthode, le type précis de l'objet sur lequel la méthode va s'appliquer. Il lui suffit de savoir que cet objet implémentera la méthode.
La surcharge de fonction consiste à ajouter à une classe une méthode portant le même nom qu’une méthode existant dans une classe et de changer un de ses paramètres.
On parle d’héritage dynamique lorsqu’un choix est fait au moment de l’exécution (exemple le choix d’une méthode) et non à la compilation.
L'algorithme est un moyen pour le programmeur de présenter son approche du problème à d'autres personnes. En effet, un algorithme est l'énoncé dans un langage bien défini d'une suite d'opérations permettant de répondre au problème. Un algorithme doit donc être :
Lisible : l'algorithme doit être compréhensible même par un non-informaticien
de haut niveau : l'algorithme doit pouvoir être traduit en n'importe quel langage de programmation, il ne doit donc pas faire appel à des notions techniques relatives à un programme particulier ou bien à un système d'exploitation donné
précis : chaque élément de l'algorithme ne doit pas porter à confusion, il est donc important de lever toute ambiguïté
concis : un algorithme ne doit pas dépasser une page. Si c'est le cas, il faut décomposer le problème en plusieurs sous-problèmes
structuré: un algorithme doit être composé de différentes parties facilement identifiables.
Un algorithme est dit récursif s'il s'appelle lui-même.
Exemple : Les boucles
Préfix : d’abord la racine, puis récursivement le sous-arbre de gauche, puis le sous-arbre de droite
Infix : d’abord récursivement le sous-arbre de gauche (le plus en bas à gauche), puis la racine, puis récursivement le sous-arbre de droite
Postfix : d’abord récursivement les sous-arbres de gauche (le plus en bas à gauche) et de droite, puis la racine
Les algorithmes lents :
Le tri par sélection : Le tri par sélection est une des méthodes de tri les plus simples. On commence par rechercher le plus grand élément du tableau que l’on va mettre à sa place : c’est à dire l’échanger avec le dernier élément. Puis on recommence avec le deuxième élément le plus grand, etc...
Le trie par insertion : Le tri par insertion est généralement le tri que l’on utilise pour classer des documents : on commence par prendre le premier élément à trier que l’on place en position 1. Puis on insère les éléments dans l’ordre en plaçant chaque nouvel élément à sa bonne place. Pour procéder à un tri par insertion, il suffit de parcourir une liste : on prend les éléments dans l’ordre. Ensuite, on les compare avec les éléments précédents jusqu’à trouver la place de l’élément qu’on considère. Il ne reste plus qu’à décaler les éléments du tableau pour insérer l’élément considéré à sa place dans la partie déjà triée.
Les algorithmes rapides :
Le tri fusion :
L'algorithme peut s'effectuer récursivement : 1 On
découpe en deux parties à peu près égales
les données à trier, 2 On trie les données de
chaque partie 3 On fusionne les deux parties ; La récursivité
s'arrête à un moment car on finit par arriver à
des listes de 1 élément et alors le tri est trivial.
On peut aussi faire dans l'autre sens : 1 On trie les éléments
deux à deux, 2 On fusionne les listes obtenues, 3 On
recommence l'opération précédente jusqu'à
ce qu'on ait une seule liste triée.
Deux fois moins rapide
que le tri rapide.
Le tri rapide : Le tri rapide est une des méthodes de tri les plus rapide. L’idée est de prendre un élément au hasard (par exemple le premier) que l’on appelle pivot et de le mettre à sa place définitive en plaçant tous les éléments qui sont plus petits à sa gauche et tous ceux qui sont plus grands à sa droite. On recommence ensuite le tri sur les deux sous tableaux obtenus jusqu’à ce que le tableau soit trié.
Le « cycle de vie d'un logiciel » désigne toutes les étapes du développement d'un logiciel, de sa conception à sa disparition. L'objectif d'un tel découpage est de permettre de définir des jalons intermédiaires permettant la validation du développement logiciel, c'est-à-dire la conformité du logiciel avec les besoins exprimés, et la vérification du processus de développement, c'est-à-dire l'adéquation des méthodes mises en œuvre.
L'origine de ce découpage provient du constat que les erreurs ont un coût d'autant plus élevé qu'elles sont détectées tardivement dans le processus de réalisation. Le cycle de vie permet de détecter les erreurs au plus tôt et ainsi de maîtriser la qualité du logiciel, les délais de sa réalisation et les coûts associés.
Le cycle de vie du logiciel comprend généralement a minima les activités suivantes :
Définition des objectifs, consistant à définir la finalité du projet et son inscription dans une stratégie globale.
Analyse des besoins et faisabilité, c'est-à-dire l'expression, le recueil et la formalisation des besoins du demandeur (le client) et de l'ensemble des contraintes.
Conception générale. Il s'agit de l'élaboration des spécifications de l'architecture générale du logiciel.
Conception détaillée, consistant à définir précisément chaque sous-ensemble du logiciel.
Codage (Implémentation ou programmation), soit la traduction dans un langage de programmation des fonctionnalités définies lors de phases de conception.
Tests unitaires, permettant de vérifier individuellement que chaque sous-ensemble du logiciel est implémentée conformément aux spécifications.
Intégration, dont l'objectif est de s'assurer de l'interfaçage des différents éléments (modules) du logiciel. Elle fait l'objet de tests d'intégration consignés dans un document.
Qualification (ou recette), c'est-à-dire la vérification de la conformité du logiciel aux spécifications initiales.
Documentation, visant à produire les informations nécessaires pour l'utilisation du logiciel et pour des développements ultérieurs.
Mise en production,
Maintenance, comprenant toutes les actions correctives (maintenance corrective) et évolutives (maintenance évolutive) sur le logiciel.
La séquence et la présence de chacune de ces activités dans le cycle de vie dépendent du choix d'un modèle de cycle de vie entre le client et l'équipe de développement.
Le modèle de cycle de vie en V part du principe que les procédures de vérification de la conformité du logiciel aux spécifications doivent être élaborées dès les phases de conception.

UML (en anglais Unified Modeling Language, « langage de modélisation unifié ») est un langage graphique de modélisation des données et des traitements. C'est une formalisation très aboutie et non-propriétaire de la modélisation objet utilisée en génie logiciel.
Le modèle UML est composé de 13 types de diagrammes (9 en UML 1.3). UML n'étant pas une méthode, leur utilisation est laissée à l'appréciation de chacun, même si le diagramme de classes est généralement considéré comme l'élément central d'UML; des méthodologies, telles que l'UnifiedProcess, axent l'analyse en tout premier lieu sur les diagrammes de cas d'utilisation (Use Case). De même, on peut se contenter de modéliser seulement partiellement un système, par exemple certaines parties critiques.
UML se décompose en plusieurs sous-ensembles
Les vues : Les vues sont les observables du système. Elles décrivent le système d'un point de vue donné, qui peut être organisationnel, dynamique, temporel, architectural, géographique, logique, etc. En combinant toutes ces vues il est possible de définir (ou retrouver) le système complet.
Les diagrammes : Les diagrammes sont des éléments graphiques. Ceux-ci décrivent le contenu des vues, qui sont des notions abstraites. Les diagrammes peuvent faire partie de plusieurs vues.
Les modèles d'élément : Les modèles d'élément sont les briques des diagrammes UML, ces modèles sont utilisés dans plusieurs types de diagramme. Exemple d'élément : cas d'utilisation (CU ou cadut), classe, association, etc.
Langage B : La méthode B est une méthode formelle de développement logiciel qui permet de modéliser de façon abstraite dans le langage de B le comportement d'un programme, puis par raffinements successifs, d'aboutir à un modèle concret, sous-ensemble du langage transcodable en Ada ou en C.
SADT : standard de description graphique d'un système complexe par analyse fonctionnelle descendante, c'est-à-dire que l'analyse chemine du général (dit "niveau A0") vers le particulier et le détaillé (dits "niveaux Aijk"). SADT est une démarche systémique de modélisation d'un système complexe ou d'un processus opératoire.
Avantages :
Structure hiérarchisée par niveau permettant une clarification et une décomposition analytique de la complexité d'un système.
Diagramme intemporel.
Inconvénients :
Pas de représentation séquentielle.
Absence d'opération en logique booléenne (ET, OU, etc).
Impossibilité d'une vue globale.
Une fonction est représentée par une "boîte" ou "module" SADT (datagramme ou actigramme). Une boite SADT est située dans son contexte avec les autres boites ou modules, par l'intermédiaire de flèches de relation. Ces flèches symbolisent les contraintes de liaisons entre boites. Elles ne font pas office de commande ou de séquencement au sens strict.
Une boite SADT se représente par un rectangle contenant :
un verbe à l'infinitif définissant l'action et la valeur ajoutée de la fonction ainsi que
son label Aijk d'identification (ex: A253: "Dimensionner un roulement à billes"), la lettre A du label signifiant "Activité",
Sur cette boite aboutissent ou partent :
des flèches d'entrée horizontales représentant la matière d'œuvre (souvent à caractère informationnel et immatériel),
des flèches d'entrée verticales descendantes représentant les contraintes de contrôle (souvent à caractère informationnel et immatériel),
des flèches d'entrée verticales remontantes représentant les contraintes (souvent à caractère physique et matériel) de la boite,
des flèches de sortie horizontales représentant la valeur ajoutée de la fonction (souvent à caractère informationnel et immatériel).
(Les sorties d'une boite peuvent bien entendu, être les entrées matière d'oeuvre ou les contrôles d'une (ou plusieurs) autre boite).
La fonction courante Aijk peut ensuite être décomposée au niveau inférieur, noté Aijk+, pour faire apparaître les sous-fonctions constituantes (ex: activité A253+ comprenant 3 sous-fonctions: A2531: "Choisir les plages de vitesses et les efforts de fonctionnement du roulement à billes", A2532: "Identifier les types de roulements à billes possibles (à billes, à rouleaux coniques, à rouleaux cylindriques, ...)", A2533: "Choisir les paramètres géométriques du roulement dans le catalogue fabriquant").
Merise :
Merise est une méthode d'analyse, de conception et de gestion de projet complètement intégrée, ce qui en constitue le principal atout. Elle a fourni un cadre méthodologique et un langage commun et rigoureux à une génération d'informaticiens français.
Les Design Patterns (en français Patrons de conception, Modèles de conception ou encore Motifs de conception sont un recueil de bonnes pratiques de conception pour un certain nombre de problèmes récurrents en programmation orientée objet.
Le concept de Design Pattern est issu des travaux de 4 personnes (Erich Gamma, Richard Helm, Ralph Johnson, et John Vlissides connus sous le patronyme de « Gang of Four ») dans leur ouvrage « Design Patterns: Elements of Reusable Object-Oriented Software » édité en 1995 et proposant 23 motifs de conception.
Un motif de conception peut être vu comme un document formalisant la structure d'une classe permettant de répondre à une situation particulière. Les motifs de conception sont classifiés selon trois grandes familles :
Motifs de création : Motif Abstract Factory, Motif Builder, Motif Factory Method, Motif Prototype, Motif Singleton.
Motifs de structuration : Motif Adapter, Motif Bridge, Motif Composite, Motif Decorator, Motif Facade, Motif Flyweight, Motif Proxy.
Motifs de comportement : Motif Chain of Responsibility, Motif Command, Motif Interpreter, Motif Iterator, Motif Mediator, Motif Memento, Motif Observer, Motif State, Motif Strategy, Motif Template Method, Motif Visitor.
Voici quelques exemples de motifs de conception :
Motif MVC (Modèle-Vue-Contrôleur) : il part du principe que toute application peut être décomposée en trois couches séparées :
Modèle, c'est-à-dire les données
Vue, c'est-à-dire la représentation des données
Controîleur, c'est-à-dire le traitement sur les données en vue de leur représentation.
Motif Proxy définissant un objet intermédiaire ayant procuration pour effectuer de manière transparente pour l'utilisateur les appels de méthodes à un objet distant.
Dans les bases de données relationnelles, une table est un ensemble de données (les valeurs) organisé selon un modèle de lignes (horizontales) et de colonnes (verticales). Chaque table est l'implémentation physique d'une relation entre les différents champs. Chaque correspondance est définie par une ligne de la table, et les valeurs d'un champ sont dans une même colonne.
C’est un logiciel fournissant des services d’interrogations, de consultations, de mise à jours, d’insertions et de destruction sur une base de donnée. Il décrit l’organisation des données et se charge de l’implémentation physique.
Il utilise un langage dit assertionnel car il suffit de spécifier les critères que doivent vérifier les données pour les obtenir (langages de 4ème génération).
Les fonctions d’un SGBD sont :
Ajout de données : un SGBD doit permettre l'ajout de données. Pour cela, il est tout d'abord nécessaire de pouvoir décrire les données avec un langage de description de données (LDD). Une fois les données décrites, on peut ajouter des valeurs qui correspondent à la description qu'on a faite par le biais d'un langage de manipulation de données (LMD).
Mise à jour des données : les données doivent être modifiables. On doit pouvoir changer la définition des données et les valeurs des données grâce au LDD et LMD respectivement.
Recherche des données : la recherche des données est un point crucial. Il faut que le SGBD puisse restituer les données rapidement.
Les méthodes d’accès aux données sont :
Modèle hiérarchique : organise les données de façon arborescente, chaque élément n’a qu’un supérieur.
Modèle réseau : extension du modèle hiérarchique ; établit des connexion entre les éléments
Modèle relationnel : chaque table est constituée de plusieurs colonnes. Les données sont stockées sous la forme de relations dans les tables, car on connaît à l’avance les interrogations que l’on effectuera. Ex Oracle
Modèle objet : OODB
Structured Query Language ; langage d’interrogation d’une base de donnes.
Langage spécialisé pour l’interrogation des bases de données relationnelles développé à partir du modèle relationnel d'E.F. CODD.
C'est un langage naturel issu directement de la théorie des ensembles.
SQL est utilisé pour accéder aux bases de données :
ASE - Adaptative Server Enterprise (Sybase)
DB2 (IBM)
Oracle 10g
PostgreSQL
SQL Server (Microsoft)
La dernière version est SQL2003, normalisée par l'ANSI
La description des fichiers est contenue dans le programme et les noms sont propres aux applications ainsi que les fonctions d’accès.
Concurrence d’accès non prévu pour la gestion des fichiers.
MySQL
PostgresSQL
Une jointure est une combinaison des enregistrements de deux tables disposant de valeurs correspondantes dans un champ déterminé de chaque table (souvent ayant le même nom dans les deux).
La table résultante est construite temporairement en fonction des prédicats spécifiés dans la requête. En SQL, ils peuvent être définis par la clause WHERE.
American National Standard Institute : Commission américaine chargée de valider et de normaliser des applications techniques, entre autres dans les domaines de l'informatique. Ainsi, les fabricants de disques durs, par exemple, font des propositions visant à intégrer de nouvelles technologies, que l'Ansi se charge de valider ou non. Si cela est le cas, on dit qu'une caractéristique est à la norme Ansi. En revanche, le fait qu'une technologie ne soit pas normalisée par cette commission n'empêche nullement un constructeur de l'intégrer à ses nouveaux produits.
La gestion numérique des droits ou GND (en anglais Digital Rights Management - DRM) a pour objectif de contrôler par des mesures techniques de protection l'utilisation qui est faite des œuvres numériques. La technique se voulant suffisante et nécessaire au contrôle, elle prévoit par exemple de :
rendre impossible la consultation d'une œuvre hors de la zone géographique prévue (les zones des DVD) ;
rendre impossible l'utilisation de matériel concurrent pour consulter une œuvre (incompatibilité des verrous appliqués aux formats musicaux, comme ceux de l'iTunes Store) ;
rendre impossible la consultation d'une œuvre selon ses préférences (désactivation de l'avance rapide sur certains passages publicitaires de DVD) ;
limiter ou rendre impossible le transfert des œuvres d'un appareil à l'autre (limitation de la copie) ;
rendre impossible l'extraction numérique de passage de l'œuvre.
Tendance voisine, l'interdiction légale de contourner ces limitations techniques est de plus en plus largement adoptée (DMCA aux États-Unis, DADVSI en France) car elle a fait l'objet d'un accord international.
DRM est parfois traduit par « gestion des droits numériques » : il s'agit là d'un contresens, car ce sont les contenus et leur gestion qui sont numériques, et non les droits eux-mêmes.
Droit d’Auteur et Droits Voisins dans la Société de l’Information » est une loi française issue de la transposition en droit français de la directive européenne 2001/29/CE sur l'harmonisation de certains aspects du droit d'auteur et des droits voisins dans la société de l'information.
Elle interdit la production de matériel et logiciel contournant les limitations, y compris pour proposer des moyens innovants et respectant les droits d'auteur, d'utiliser les œuvres.
La Licence publique générale GNU, ou GNU General Public License (son seul nom officiel en anglais, communément abrégé GNU GPL voire simplement couramment « GPL ») est une licence qui fixe les conditions légales de distribution des logiciels libres du projet GNU.
Elle a depuis été adopté, en tant que document définissant le mode d'utilisation, donc d'usage et de diffusion, par de nombreux auteurs de logiciels libres. La principale caractéristique de la GPL est le copyleft, ou gauche d'auteur, qui consiste à « détourner » le principe du copyright (ou droit d'auteur) pour préserver la liberté d'utiliser, d'étudier, de modifier et de diffuser le logiciel et ses versions dérivées.
L'objectif de la licence GNU GPL, selon ses créateurs est de garantir à l'utilisateur les droits suivants (appelés libertés) sur un programme informatique :
la liberté d'exécuter le logiciel, pour n'importe quel usage ;
la liberté d'étudier le fonctionnement d'un programme et de l'adapter à ses besoins, ce qui passe par l'accès aux codes sources ;
la liberté de redistribuer des copies ;
la liberté d'améliorer le programme et de rendre publiques les modifications afin que l'ensemble de la communauté en bénéficie.
Projet de standardisation des APIs des logiciels destinés à fonctionner sur des variantes du système d'exploitation UNIX ; Portable Operating System Interface, dont le X exprime l'héritage UNIX de l'API.
POSIX spécifie dans 17 documents différents les interfaces utilisateurs et les interfaces logicielles. Actuellement, la documentation de POSIX est divisée en trois parties :
les API (permet de définir la manière dont un composant informatique peut communiquer avec un autre) de base (qui comprennent des extensions à POSIX.1, les services temps réel, les processus légers, les extensions temps réel, l'interface de sécurité, l'accès aux fichiers par le réseau, et les communications inter-processus par le réseau) ;
les commandes et utilitaires POSIX (extensions de portabilité des utilisateurs, corrections et extensions, utilitaire de protection et de contrôle, utilitaires pour le traitement par lots) ;
test de conformité à POSIX.
La Linux Standard Base LSB est un projet joint par nombre de distributions Linux sous la structure organisationnelle du Free Standards Group afin de concevoir et standardiser la structure interne des systèmes d'exploitation basés sur GNU/Linux. La LSB est basée sur les spécifications POSIX, la « spécification unique d'UNIX », ainsi que sur d'autres nombreux standards ouverts, mais l'étend dans certains domaines.
D'après eux :
« Le but du LSB est de développer et promouvoir un ensemble de standards qui augmenteront la compatibilité entre les différentes distributions Linux et permettront aux applications de s'exécuter sur n'importe quel système conforme au LSB. De plus, la LSB aidera à coordonner les efforts des vendeurs de logiciels pour porter et réaliser des produits pour Linux. »
La conformité à la LSB pour un produit doit être certifié par une procédure. La réalisation de cette dernière appartient à l'Open Group en coopération avec le Free Standards Group.
La LSB spécifie par exemple :
un ensemble de bibliothèque standard,
un nombre de commandes et d'utilitaires qui étendent le standard POSIX,
la structure de la hiérarchie du système de fichiers,
les différents run levels,
et plusieurs extensions à X Window System.
The Single UNIX Specification (SUS) is the collective name of a family of standards for computer operating systems to qualify for the name "Unix". The SUS is developed and maintained by the Austin Group, based on earlier work by the IEEE and The Open Group.
he user and software interfaces to the OS are specified in four main sections:
Base Definitions - a list of definitions and conventions used in the specifications and a list of C header files which must be provided by compliant systems.
Shell and Utilities - a list of utilities and a description of the shell, sh.
System Interfaces - a list of available C system calls which must be provided.
Rationale - the explanation behind the standard.
The standard user command line and scripting interface is the POSIX shell, an extension of the Bourne Shell based on an early version of the Korn Shell. Other user-level programs, services and utilities include awk, echo, ed, vi, and hundreds of others. Required program-level services include basic I/O (file, terminal, and network) services.
A test suite accompanies the standard. It is called PCTS or the Posix Certification Test Suite.
Note that a system need not include source code derived in any way from AT&T Unix to meet the specification. For instance, IBM OS/390, now z/OS, qualifies as a "Unix" despite no code in common.
Créer en 1978. Appartient au ministère de la justice ; 17 membres élues pour 5 ans (député, sénateur, Cour de cassation, cour des comptes, etc..)
Rôle :
Surveille les bases de données d’information nominative.
Garantie l’accès aux utilisateurs de leurs données.
Règlemente les normes à respecter.
Donne sont avis sur des déclarations de base de données nominatives.
Autorise la création de base de donnée nominative.
Renseigne le gouvernement sur l’évolution des techniques.
ISO 8402-94 définit la qualité comme suit : « Ensemble des caractéristiques d'une entité qui lui confèrent l'aptitude à satisfaire des besoins exprimés et implicites. »
La norme ISO 9000:2000 la définit comme ceci : « Aptitude d'un ensemble de caractéristiques intrinsèques à satisfaire des exigences. »
Dans la pratique la qualité se décline sous deux formes :
La qualité externe, correspondant à la satisfaction des clients. Il s'agit de fournir un produit ou des services conformes aux attentes des clients afin de les fidéliser et ainsi améliorer sa part de marché. Les bénéficiaires de la qualité externe sont les clients d'une entreprise et ses partenaires extérieurs. Ce type de démarche passe ainsi par une écoute nécessaire des clients mais doit permettre également de prendre en compte des besoins implicites, non exprimés par les bénéficiaires.
La qualité interne, correspondant à l'amélioration du fonctionnement interne de l'entreprise. L'objet de la qualité interne est de mettre en oeuvre des moyens permettant de décrire au mieux l'organisation, de repérer et de limiter les dysfonctionnements. Les bénéficiaires de la qualité interne sont la direction et les personnels de l'entreprise. La qualité interne passe généralement par une étape d'identification et de formalisation des processus internes réalisés grâce à une démarche participative.
Internet Engineering Task Force : chargé de définir des recommandations visant à faire évoluer Internet.
Internationnal Standardization Organisation : organisme de normalisation pour les réseaux informatiques dépendant de l’ONU.
Union Internationnal des Télécommunication ex CCITT
XML (entendez eXtensible Markup Language et traduisez Langage à balises étendu, ou Langage à balises extensible) est en quelque sorte un langage HTML amélioré permettant de définir de nouvelles balises. Il s'agit effectivement d'un langage permettant de mettre en forme des documents grâce à des balises (markup).
La force de XML réside dans sa capacité à pouvoir décrire n'importe quel domaine de données grâce à son extensibilité. Il va permettre de structurer, poser le vocabulaire et la syntaxe des données qu'il va contenir.
En réalité les balises XML décrivent le contenu plutôt que la présentation (contrairement À HTML). Ainsi, XML permet de séparer le contenu de la présentation.. Ce qui permet par exemple d'afficher un même document sur des applications ou des périphériques différents sans pour autant nécessiter de créer autant de versions du document que l'on nécessite de représentations !
XML est un sous ensemble de SGML (Standard Generalized Markup Language), défini par le standard ISO8879 en 1986, utilisé dans le milieu de la Gestion Electronique Documentaire (GED). XML reprend la majeure partie des fonctionnalités de SGML, il s'agit donc d'une simplification de SGML afin de le rendre utilisable sur le web !
XML est un format de description des données et non de leur représentation, comme c'est le cas avec HTML. La mise en page des données est assurée par un langage de mise en page tiers. A l'heure actuelle (fin de l'année 2000) il existe trois solutions pour mettre en forme un document XML :
CSS (Cascading StyleSheet), la solution la plus utilisée actuellement, étant donné qu'il s'agit d'un standard qui a déjà fait ses preuves avec HTML
XSL (eXtensible StyleSheet Language), un langage de feuilles de style extensible développé spécialement pour XML. Toutefois, ce nouveau langage n'est pas reconnu pour l'instant comme un standard officiel
XSLT (eXtensible StyleSheet Language Transformation). Il s'agit d'une recommandation W3C du 16 novembre 1999, permettant de transformer un document XML en document HTML accompagné de feuilles de style
Structure des documents XML
XML fournit un moyen de vérifier la syntaxe d'un document grâce aux DTD (Document Type Definition). Il s'agit d'un fichier décrivant la structure des documents y faisant référence grâce à un langage adapté. Ainsi un document XML doit suivre scrupuleusement les conventions de notation XML et peut éventuellement faire référence à une DTD décrivant l'imbrication des éléments possibles. Un document suivant les règles de XML est appelé document bien formé. Un document XML possédant une DTD et étant conforme à celle-ci est appelé document valide.
Décodage d’un document XML
XML permet donc de définir un format d'échange selon les besoins de l'utilisateur et offre des mécanismes pour vérifier la validité du document produit. Il est donc essentiel pour le receveur d'un document XML de pouvoir extraire les données du document. Cette opération est possible à l'aide d'un outil appelé analyseur (en anglais parser, parfois francisé en parseur).
Le parseur permet d'une part d'extraire les données d'un document XML (on parle d'analyse du document ou de parsing) ainsi que de vérifier éventuellement la validité du document.
Les principaux atouts de XML :
La lisibilité : aucune connaissance ne doit théoriquement être nécessaire pour comprendre un contenu d'un document XML
Autodescriptif et extensible
Une structure arborescente : permettant de modéliser la majorité des problèmes informatiques
Universalité et portabilité : les différents jeux de caractères sont pris en compte
Déployable : il peut être facilement distribué par n'importe quels protocoles à même de transporter du texte, comme HTTP
Intégrabilité : un document XML est utilisable par toute application pourvue d'un parser (c'est-à-dire un logiciel permettant d'analyser un code XML)
Extensibilité : un document XML doit pouvoir être utilisable dans tous les domaines d'applications
Ainsi, XML est particulièrement adapté à l'échange de données et de documents.
L'intérêt de disposer d'un format commun d'échange d'information dépend du contexte professionnel dans lequel les utilisateurs interviennent. C'est pourquoi, de nombreux formats de données issus de XML apparaissent (il en existe plus d'une centaine) :
OFX : Open Financial eXchange pour les échanges d'informations dans le monde financier
MathML : Mathematical Markup Language permet de représenter des formules mathématiques
CML : Chemical Markup Language permet de décrire des composés chimiques
SMIL : Synchronized Multimedia Integration Language permet de créer des présentations multimédia en synchronisant diverses sources : audio, vidéo, texte,...
XML permet d'utiliser un fichier afin de vérifier qu'un document XML est conforme à une syntaxe donnée. La norme XML définit ainsi une définition de document type appelée DTD (Document Type Definition), c'est-à-dire une grammaire permettant de vérifier la conformité du document XML. La norme XML n'impose pas l'utilisation d'une DTD pour un document XML, mais elle impose par contre le respect exact des règles de base de la norme XML.
Ainsi on parlera de:
document valide pour un document XML comportant une DTD
document bien formé pour un document XML ne comportant pas de DTD mais répondant aux règles de base du XML
Une DTD peut être définie de 2 façons :
sous forme interne, c'est-à-dire en incluant la grammaire au sein même du document
sous forme externe, soit en appelant un fichier contenant la grammaire à partir d'un fichier local ou bien en y accédant par son URL
Les ERP (en anglais Enterprise Resource Planning), aussi appelés Progiciels de Gestion Intégrés (PGI), sont des applications dont le but est de coordonner l'ensemble des activités d'une entreprise (activités dites verticales telles que la production, l'approvisionnement ou bien horizontales comme le marketing, les forces de vente, la gestion des ressources humaines, etc.) autour d'un même système d'information.
Les Progiciels de Gestion Intégrés contiennent généralement des outils de Groupware et de Workflow afin d'assurer la transversalité et la circulation de l'information entre les différents services de l'entreprise.
Le terme "ERP" provient du nom de la méthode MRP (Manufacturing Resource Planning) utilisée depuis les années 70 pour la gestion et la planification de la production industrielle.
On appelle "WorkFlow" (traduisez littéralement "flux de travail") la modélisation et la gestion informatique de l'ensemble des tâches à accomplir et des différents acteurs impliqué dans la réalisation d'un processus métier (aussi appelé processus opérationnel). Le terme de Workflow pourrait donc être traduit en français par Gestion électronique des processus métier.
Un processus métier représente les interactions sous forme d'échange d'informations entre divers acteurs tels que :
des humains,
des applications ou services,
des processus tiers.
De façon pratique, un WorkFlow peut décrire :
le circuit de validation,
les tâches à accomplir entre les différents acteurs d'un processus,
les délais à respecter,
les modes de validation
Il fournit en outre, à chacun des acteurs, les informations nécessaires pour la réalisation de sa tâche. Pour un processus de publication en ligne par exemple, il s'agit de la modélisation des tâches de l'ensemble de la chaîne éditoriale, de la proposition du rédacteur à la validation par le responsable de publication :

Figure 22 : exemple de WorkFlow
L'exemple ci-dessus est une représentation très schématique de ce que pourrait être un workflow de publication de document sur un Intranet à l'aide d'une interface de publication :
Le rédacteur propose un article au chef de rubrique
Le chef de rubrique regarde le document et le valide
Le rédacteur en chef trouve que le document possède des éléments incompatibles avec l'actualité et retourne le document au rédacteur
Le rédacteur revoit sa copie et la soumet au chef de rubrique
Le chef de rubrique corrige quelques coquilles et transmet l'article au rédacteur en chef
Le rédacteur en chef valide le document pour une publication en ligne
On distingue généralement deux types de Workflow :
Le workflow procédural (aussi appelé workflow de production ou workflow directif) correspondant à des processus métiers connus de l'entreprise et faisant l'objet de procédures pré-établies : le cheminement du workflow est plus ou moins figé ;
Le workflow ad hoc basé sur un modèle collaboratif dans lequel les acteurs interviennent dans la décision du cheminement : le cheminement du workflow est dynamique.
Le moteur de workflow est l'outil permettant de modéliser et d'automatiser les processus métiers de l'entreprise. Ce type d'outil permet ainsi de formaliser les règles métier de l'entreprise afin d'automatiser la prise de décision, c'est-à-dire la branche du workflow à choisir, en fonction du contexte donné.
L'objet de l'EAI (Enterprise Application Integration, traduisez intégration des applications de l'entreprise) est l'interopérabilité et l'organisation de la circulation de l'information entre des applications hétérogènes, c'est-à-dire faire communiquer les différentes applications constituant le système d'information de l'entreprise, voire même celles des clients, des partenaires ou des fournisseurs.
Un projet d'EAI consiste donc dans un premier temps à mettre en place une architecture dans laquelle les différentes applications communiquent entre elles. Il s'agit donc de développer des connecteurs (middleware) permettant d'interfacer des applications utilisant des protocoles de communications différents (généralement propriétaires).
Toutefois le projet d'EAI va au-delà de l'interopérabilité entre les applications : il permet de définir un workflow entre les applications et constitue ainsi une alternative aux ERP avec une approche plus modulaire.
Néanmois, l'EAI conserve des limites liées à la rigidité de l'existant (appelé legacy, traduisez héritage), si bien qu'il est nécessaire de modifier le connecteur lors de modifications importantes des applications.
On qualifie d'informatique décisionnelle (en anglais « Business intelligence », parfois appelé tout simplement « le décisionnel ») l'exploitation des données de l'entreprise dans le but de faciliter la prise de décision par les décideurs, c'est-à-dire la compréhension du fonctionnement actuel et l'anticipation des actions pour un pilotage éclairé de l'entreprise.
Les outils décisionnels sont basés sur l'exploitation d'un système d'information décisionnel alimenté grâce à l'extraction de données diverses à partir des données de production, d'informations concernant l'entreprise ou son entourage et de données économiques.
Un outil appelé ETL (Extract, Transform and Load) est ainsi chargé d'extraire les données dans différentes sources, de les nettoyer et de les charger dans un entrepôt de données.
Enfin des outils d'analyse décisionnelle permettent de modéliser des représentations à base de requêtes afin de constituer des tableaux de bord, on parle ainsi de reporting.

Figure 22 : Exemple de mise en ouvre d’ETL
Enterprise JavaBeans (EJB) est une architecture de composants logiciels côté serveur pour la plateforme de développement J2EE.
Cette architecture propose un cadre pour créer des composants distribués (c’est-à-dire déployés sur des serveurs distants) écrit en langage de programmation Java hébergés au sein d'un serveur applicatif permettant de représenter des données (EJB dit entité), de proposer des services avec ou sans conservation d'état entre les appels (EJB dit session), ou encore d'accomplir des taches de manière asynchrone (EJB dit message). Tous les EJB peuvent évoluer dans un contexte transactionnel.
Object oriented design ou POO Programmation orienté Objet
L'architecture orientée services (calque de l'anglais Service Oriented Architecture, ou SOA) est une forme d'architecture de médiation qui est un modèle d'interaction applicative qui met en œuvre des services (composants logiciels) :
avec une forte cohérence interne (par l'utilisation d'un format d'échange pivot, le plus souvent XML),
et des couplages externes « lâches » (par l'utilisation d'une couche d'interface interopérable, le plus souvent un service web WS-*).
Le service est une action exécutée par un « fournisseur » (ou « producteur ») à l'attention d'un « client » (ou « consommateur »), cependant l'interaction entre consommateur et producteur est faite par le biais d'un médiateur (qui peut être un bus) responsable de la mise en relation des composants.
Ces systèmes peuvent aussi être définis comme des couches applicatives.
L'architecture orientée services est une réponse très efficace aux problématiques que rencontrent les entreprises en termes de réutilisabilité, d'interopérabilité et de réduction de couplage entre les différents systèmes qui implémentent leurs systèmes d'information.
Elles mettent en application une partie des principes d'urbanisation.
Au sein de l'architecture orientée services, on distingue les notions d'annuaire, de bus, de contrat et de service, ce dernier étant le noyau et le point central d'une architecture orientée services.
Le service étant à grandes mailles, il englobe et propose les fonctionnalités des composants du système. La SOA est un concept d'architecture, la WSOA (WebService Oriented Architecture) en est sa déclinaison ou plus précisément son implémentation avec des WebService.
Le service est l'unité atomique d'une architecture SOA. Une application est un ensemble de services qui dialoguent entre eux par des messages.
Le couplage entre services est un couplage lâche et les communications peuvent être synchrones ou asynchrones.
Le service peut:
être codé dans n'importe quel langage,
s'exécuter sur n'importe quelle plateforme (matérielle et logicielle).
Le service doit :
offrir un ensemble d'opérations dont les interfaces sont publiées,
être autonome (disposer de toutes les informations nécessaires à son exécution : pas de notion d'état)
respecter un ensemble de contrats (règles de fonctionnement).
Concept pour formaliser ou modéliser l'agencement du système d'information (SI) de l'entreprise.
L’urbanisation informatique définit l'organisation d’un système d'information (SI) à l’image d’une ville.
Elle vise à un SI capable de soutenir et d’accompagner la stratégie de l’entreprise dans le meilleur rapport coûts/qualité/délais.
Elle permet d’améliorer la réactivité et de n’investir que dans les produits et services générateurs de valeur ajoutée, tout en maîtrisant les charges informatiques et le retour sur investissement.
Les outils d'EAI favorisent cette démarche qui peut se mettre en œuvre :
de manière opportuniste : à l’occasion d’un projet de développement, de refonte ou de maintenance,
de manière plus volontariste : dans le cadre d’un chantier d’urbanisation.
L'urbanisation consiste à découper le SI en modules autonomes, de taille de plus en plus petite :
les zones,
les quartiers (et les îlots si nécessaires),
les blocs (blocs fonctionnels).
Entre chaque module (zone, quartier, îlot, bloc) se dessinent des zones d’échange d’informations qui permettent de découpler les différents modules pour qu'ils puissent évoluer séparément tout en conservant leur capacité à interagir avec le reste du système.
Plus particulièrement, l’urbanisation vise :
à renforcer la capacité à construire et à intégrer des sous-systèmes d'origines diverses,
à renforcer la capacité à faire interagir les sous-systèmes du SI et les faire interagir avec d’autres SI (interopérabilité),
à renforcer la capacité à pouvoir remplacer certains de ces sous-systèmes (interchangeabilité).
et de manière générale pour le SI à :
favoriser son évolutivité, sa pérennité et son indépendance,
renforcer sa capacité à intégrer des solutions hétérogènes (progiciels, éléments de différentes plate-formes, etc.).